[Previously: On Teaching Coding to English Studies Students]
Recently I wrote about English studies students learning to code in an interdisciplinary computer science and English class. In that post I mentioned that this class (running for the third consecutive year) comes with a variety of challenges – some strictly institutional, some cross-departmental, and some pedagogical. I’ve been collecting a number of these and will be blogging about them in the future. In that post I also mentioned that there are two very oppositional learning curves at play: one is getting the English studies students to think about computers in a critical way and the other is getting the computer science students to read literature.
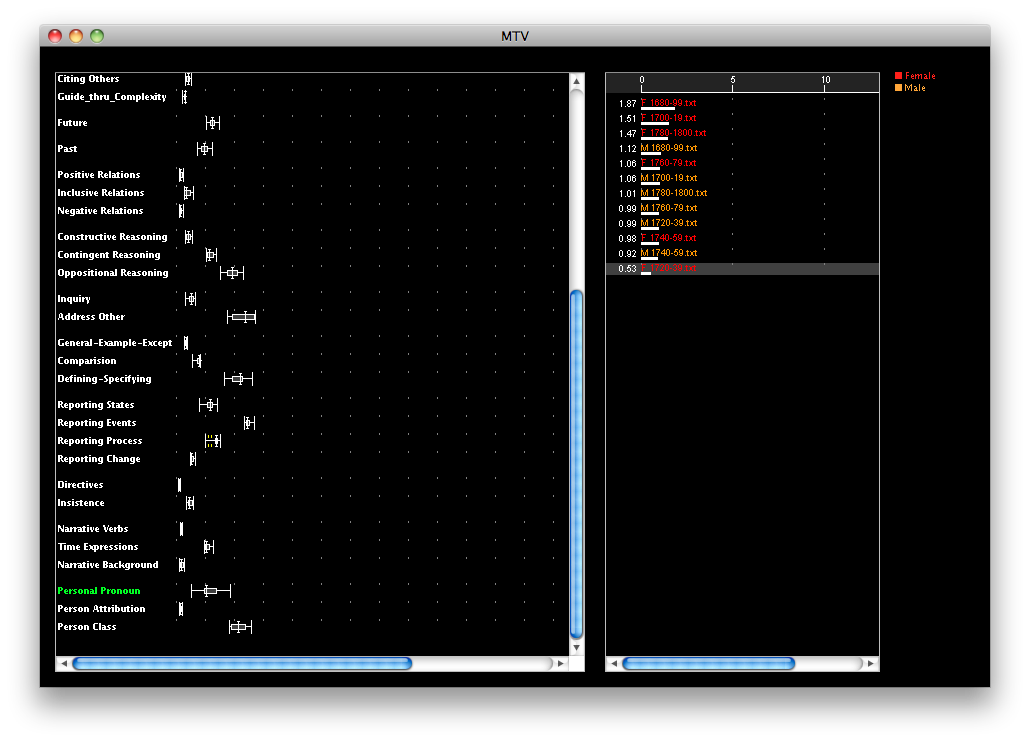
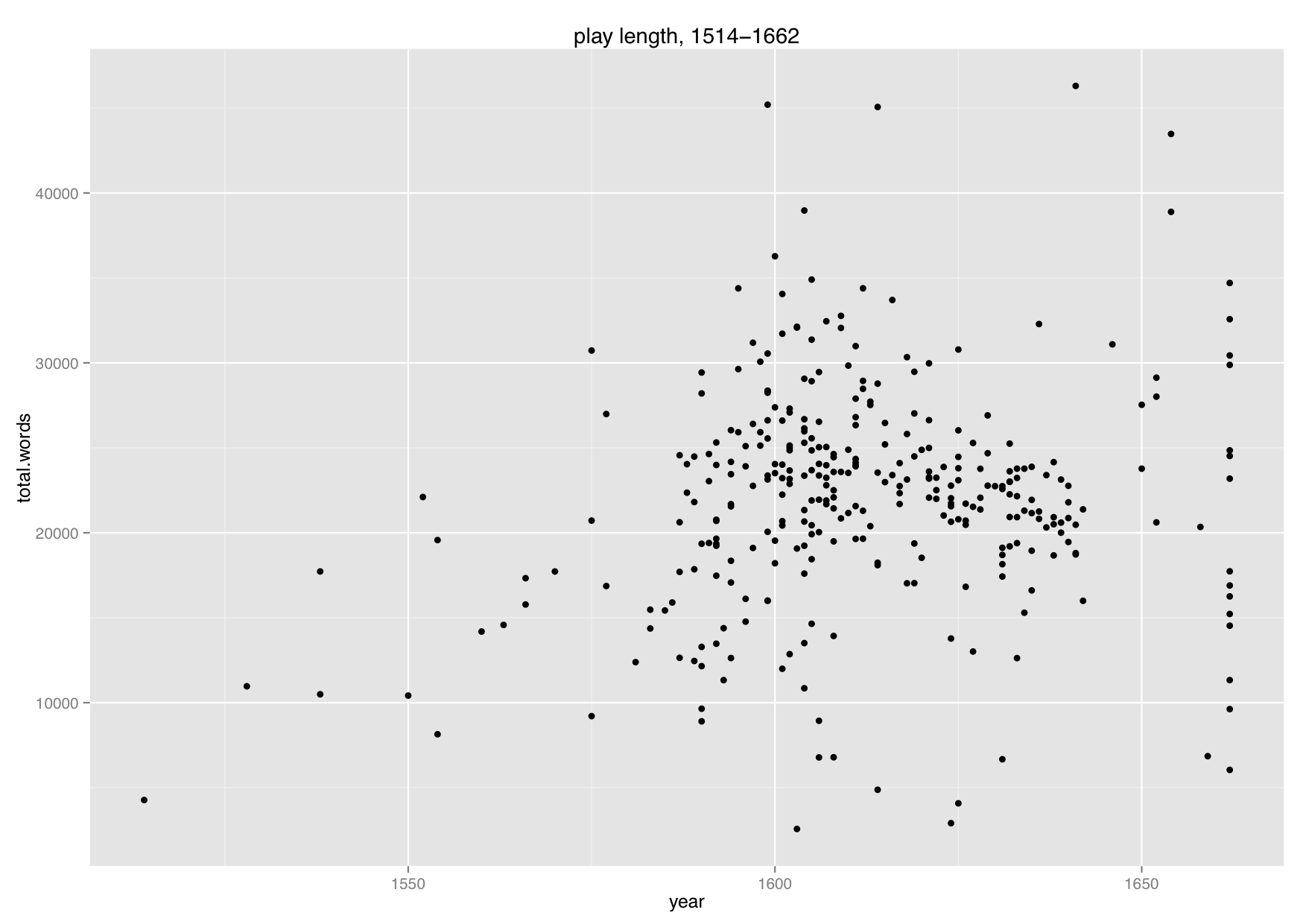
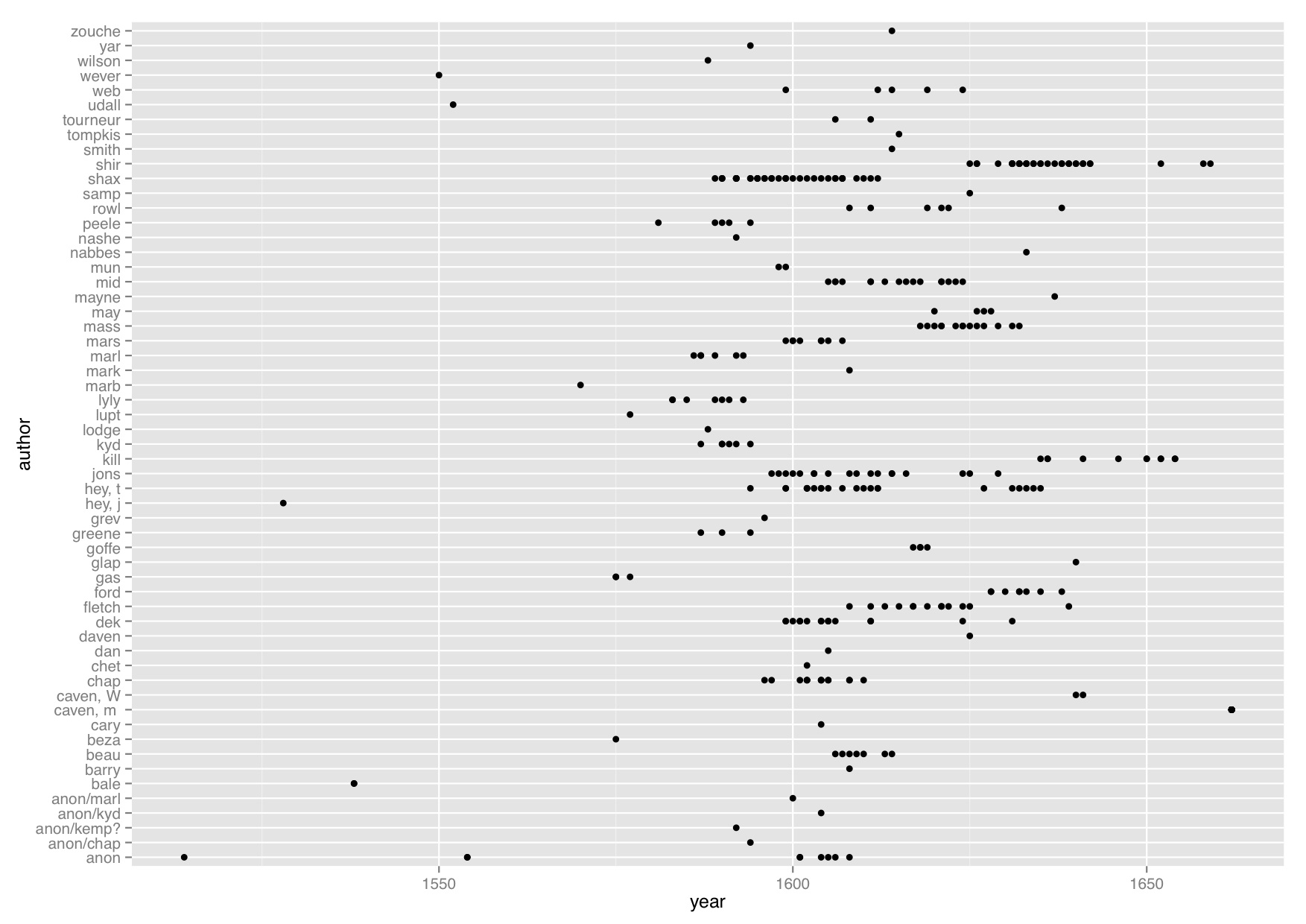
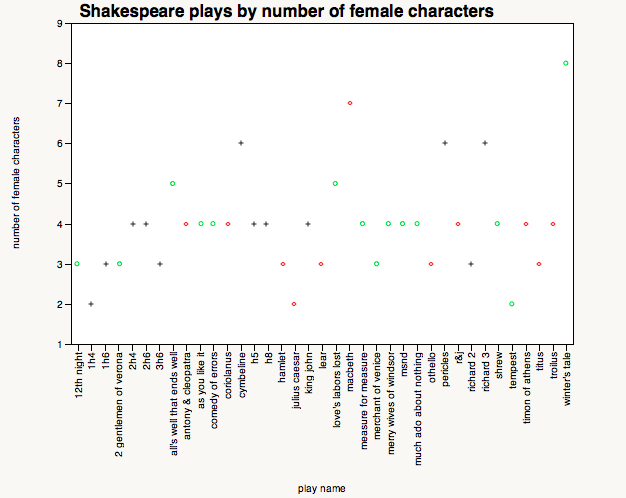
We have just hit the very exciting point in the course where the computer science students are learning to read and the English studies students are truly hitting their stride, which is a dramatic turnaround from the start of the course. Last week we asked each group to give a very short, informal presentation about their assigned Shakespeare plays in relation to the rest of the Shakespeare corpus. It was no surprise that in every group the English studies students gave an overview of the plot of their play and a few key themes whereas the computer science students reported what they had deemed to be a finding. English studies students have been studying how to analyze texts and the computer science students haven’t done that in the same way.
Here in Scotland, students begin to track either towards arts & humanities or science long before they hit university – they start to track in high school, and take school leaving exams in a number of subjects (“Highers”), from a rather long list which you can read here. Once you choose your track, it’s rare (though not unheard of) to have much overlap between A&H and science in one’s Highers qualifications. Most degree programs will have preferred subjects for applicants which guide students’ decisions about which Highers to take; Strathclyde’s entry requirements for a student wishing to be a Computer Science undergraduate can be found here (pdf). Unless you’re going into a joint honours in Computer Science and Law, English literature or language is not a required Higher for prospective students in computer science at my university. It goes the other way, too – a Higher in Maths is not a requirement for a prospective English studies student unless they plan on taking a joint honours with Mathematics (again, pdf). Some students may take Highers strictly out of interest (or uncertainty about which route to take), but like the SAT II or AP exams, this is not necessarily something you’d do for fun – these are high-stakes exams.
If faced with that choice I would definitely have taken the Arts & Humanities track despite liking science and being (told I was) very bad at math. I suspect that a lot of computer science students may have liked history or media studies but were bad at writing (or told they were…) and that was enough to turn them away from taking an Arts & Humanities track. It might be that students who sign up for a degree in Computer Science are just really passionate about computers, or that they like practical problem solving, or they’ve been told that computer science is a lucrative field. I have no idea – I’m not them*. On the surface, it can look like they have a lot of missing cultural information for not knowing things about literature – but they also know a whole lot more than we do about very different things.
That’s not to say these students don’t read of their own accord or aren’t interested in books. However, by the time they show up to my class, they have rather successfully avoided close reading for a few years, whereas English studies students have been practicing this skill for a while now. This is something English studies students are very comfortable with, and have now learned enough about the way that computers “think” (or lack thereof) to reach a common ground with the CS students.
However, in the same way the computer science students found the first half of the class easy and the English studies students found it tremendously daunting, the computer science students suddenly feel like they’ve been thrown in the deep end. The English studies students have to teach them how to analyze a text.
In our in-class presentations, each group had to discuss a discovery they’ve made about their play and explain why it was interesting. Without fail, the computer science students had lots to say about various discoveries they had found about kinds of words that were more or less frequent in their play compared to all of Shakespeare’s plays. And yet when they were pressed about why they thought it was happening, they weren’t really sure. The English studies students could postulate theories about why there were more or less of a specific kind of feature in their text, because they know how to approach this problem.
Over the next few weeks we’re letting the students self-guide their own projects and produce explanations for their discoveries, which means the computer science students are on a crash course on close-reading from their in-group local expert. They’re learning that data isn’t everything when it comes to understanding what makes their play in some way different (or similar) from other plays. In fact, they’re learning the limitations of data and ways that close-reading is not just supplementary but essential to a model of distance reading with computational methods. And if the student presentations I saw last week are any indication, I suspect I have some very exciting work coming my way in a few weeks’ time.
* I did my dual-major undergrad degree in English lit and Linguistics; I didn’t get involved in computers until my masters.
(with thanks to Kat Gupta for comments on this post)

















{kind=link}
You must be logged in to post a comment.