If you’re just joining me, I’ve been working on word frequencies of six highly-prototypical lexical items in a corpus of slightly less than 400 Early Modern London plays. I recommend starting with my research notes and then looking at some quick & dirty results.
As I noted in my quick & dirty results, these numbers hadn’t been normalized in any way: it was all raw data. In an effort to move beyond just raw data, I compiled the total number of words in each play in the corpus. I initially was interested in how play length might be a variable over time my corpus, so I graphed that. The bulk of my plays are from the early 1600s, as you can see:
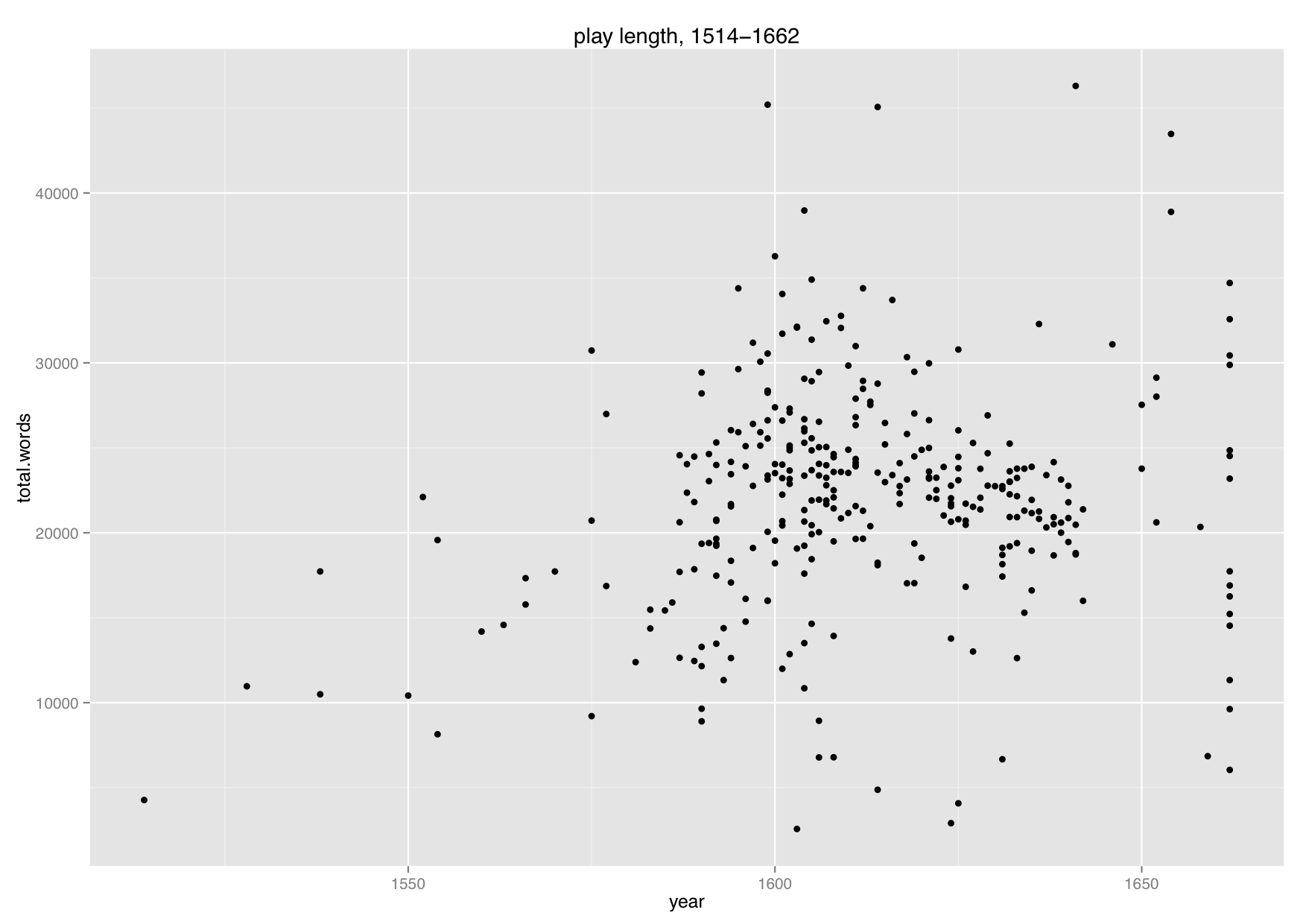
Overall, plays do seem to get longer until about 1600, at which point they start to get shorter again. 1662 looks to be an outlier here, as the plays in a straight line on the far right-hand side are mostly by Margaret Cavendish. (I am currently trying to figure out how to color my graphs by author, so if you have advice on that, please let me know: I’m rather haphazardly teaching myself to graph in R as I go.)
OK, so I have the total number of tokens in each text. What if treated every instance of my prototypical lexical items as a specific type, and plotted them as type/token ratios? Type/token ratios have a bit messy history in corpus linguistics, as they’re mostly used to calculate vocabulary denseness (Type/Token Ratios: what do they really tell us?, Richards 1987 [pdf]), but this would show a ratio of the raw frequency of each lexical item of interest in each play compared to the length of each play, which would normalize my data a bit.
Click to zoom:

First of all, it’s notable that the lexical-frequency-to-play-length ratio make some pretty clear bell-curve shapes; I haven’t tried to calculate standard deviations of play-length. (I suppose I could do that next.) The average length of an Early-Modern London play in my corpus was 22086.5 words.
It seems that as plays get longer, they’re more likely to use man (and, to some extent, wom*n) in ways that are not true for lord/lady and knave/wench. It’s also worth looking at scales here: there are nearly double the number of lords than ladys, although man/woman and knave/wench are more comparable. Also, there are way fewer instances of knave and wench in my corpus overall, which suggests that maybe these words are not nearly as popular as we might like to think.
