This is a step-by-step guide given to participants in Strathclyde’s Digital Humanities Workshop #3: AntConc, on 20 May 2014, organized by Anouk Lang. Here is a printable, scaled down handout to accompany this page. An alternative version for the slightly more advanced user is available as a Programming Historian lesson. This page is maintained semiregularly for link rot; please see the end of this post for when it was last updated. If you encounter a dead link, please let me know by sending an email to hgf5 at psu dot edu with the email title “BROKEN LINK”.
This workshop was given in a university computer lab, using PCs running Windows 7, and is pitched at folks who are comfortable with computers but would not be considered power users. There are some steps here which are easier to achieve in other ways, but I’ve chosen to start where the average computer user might begin. It hopefully goes without saying that this process will look slightly different on a Mac, but the general principles should be similar.
0 Introduction
Corpus analysis is a form of text analysis which allows you to make comparisons between textual objects at a large scale (so-called ‘distant reading’). It allows us to see things that we don’t necessarily see when reading as humans.
If you have ever…
- searched in a PDF or a word doc for all examples a specific term
- Used a biblical concordance to find all examples of a specific term
You have done this sort of thing before.
A corpus is a collection of texts, which can be anything from all of Shakespeare to Top 40 song lyrics from the past 20 years to full novels to tweets to news articles. If it is a collection of words it is analyseable!
1 Loading files and the AntConc interface
Antconc works only on PLAIN-TEXT files with the file appendix .txt (eg Hamlet.txt).
It will read XML files that are saved as .txt files.
Antconc will not read .doc, .docx, .pdf, files. You will need to convert these into .txt files.
(it’s OK if you don’t know what an xml file is today.)
1.1 Making a plain-text file.
Open http://news.stv.tv/, choose a news article (doesn’t matter which one, as long as it is primarily text)
Highlight all text in the article (header, byline, etc), and right-click “copy”. Open MSWord and select ‘paste’.
Delete any non-textual objects, such as images: we are preparing for text analysis, so we only want to retain the text. You probably want to delete their footer, as well:
Feedback: We want your feedback on our site. If you’ve got questions, spotted an inaccuracy or just want to share some ideas about our news service, please email us on web@stv.tv.
Download: The STV News app is Scotland’s favourite and is available for iPhone from the Apple store and for Android from Google Play. Download it today and continue to enjoy STV News wherever you are.
Join in: For debate, chat, comment and more, join our communities on the STV News Facebook page or follow @STVNews on Twitter.
Instead of saving it as a .doc or .docx file, we’re going to save it as a .txt file to the desktop.
File > Save as > [article title], but in the drop down menu labelled SAVE AS TYPE we’re going to choose the file type “Plain Text (.txt)”.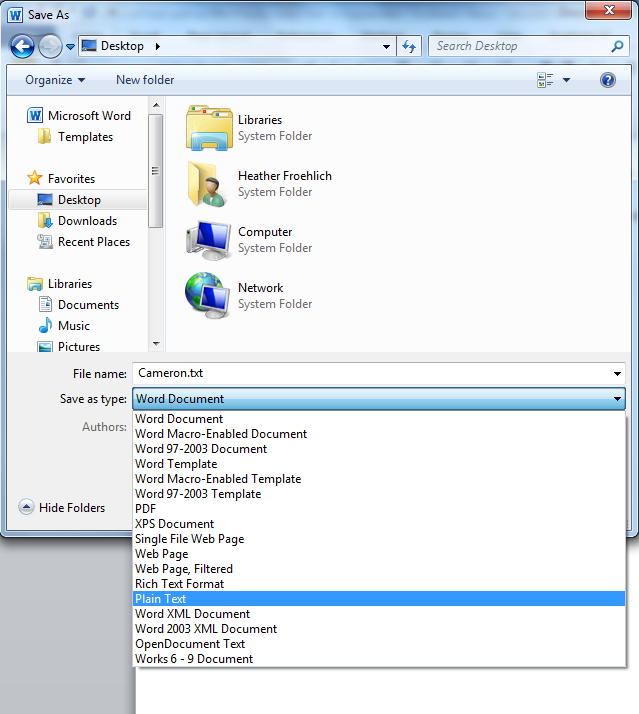
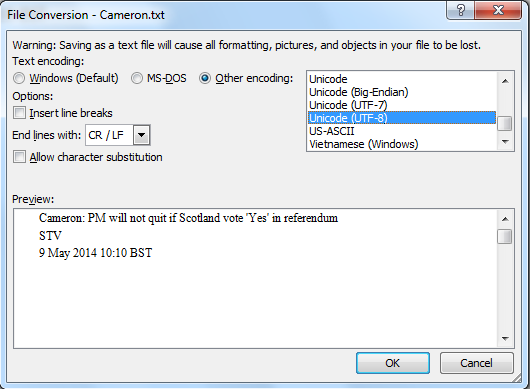
This will give you a warning: “Saving as a text file will cause all formatting, pictures, and objects in your file to be lost.” You also get an option for Text Encoding. Select Other Encoding: “Unicode (UTF-8)” and click OK.
Go to the desktop and check to see you have a file that looks like this. (Depending on some settings, It might save as ‘Cameron.txt’, or it might just save as ‘Cameron’.)
To be safe, make sure every file is saved with the .txt suffix! Each file you want to use in your corpus must be a plain text file for Antconc to use it.
You can open the file in Notepad to see what it looks like:
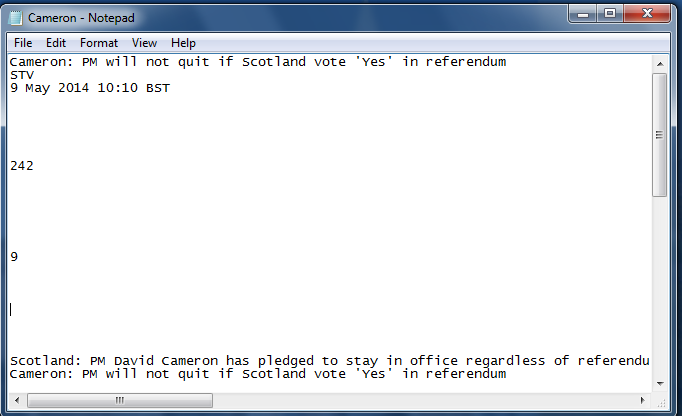
Those white spaces aren’t a problem, though you may decide you don’t need the numbers (which you can remove then save the file again.)
Repeating this a lot is how you would build a corpus of plain text files; this process is called corpus construction, which very often involves addressing questions of sampling, representativeness and organization.
Further reading on corpus construction:
Biber (1993), “Representativeness in Corpus Design”. Literary and Linguistic Computing, 8 (4): 243-257. http://llc.oxfordjournals.org/content/8/4/243.abstract
Wynne, M (ed.) (2005). Developing Linguistic Corpora: a Guide to Good Practice. Oxford: Oxbow Books. http://www.ahds.ac.uk/creating/guides/linguistic-corpora/
1.2 Using a corpus
Rather than build a corpus from the ground up, today we’re going to use a prepared corpus of positive and negative movie reviews, borrowed from the Natural Language Processing Toolkit (http://nltk.org – possibly useful for anyone interested in looking at grammatical structures.) The NLTK movie review corpus has 2000 reviews, organized by positive & negative outcomes; today we will be addressing a small subset of them (200 positive, 200 negative).
Open a new tab and go to this link to download the movie review corpus; it will take you directly to this dialog box:

Click OK and wait for the files to download. The folder should automatically unzip itself.
IF IT DOESN’T, find where the file has been saved to and:
- Right-click on the Zip file and choose Extract All
- Choose a location for the folder to be extracted into: choose Desktop
- If you checked “Show extracted files when complete”, the files or folders within the Zip folder appear.
- If you unchecked the box, a folder or file with the same name (without the Zip) should appear.
IF THE FILE UNZIPS ITSELF, it’s worth noting where these files live:
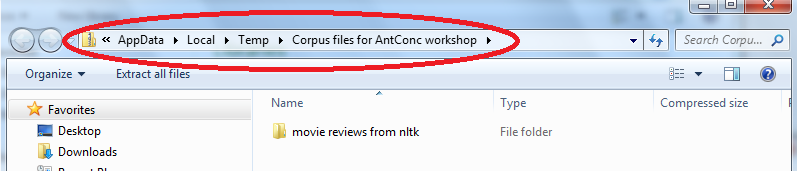
In the folder “movie reviews from nltk” you will find the following folders when you open the folder “Movie reviews from NLTK”.
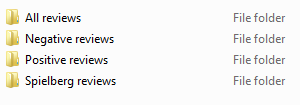 We’re going to move them somewhere more accessible – the desktop. (You may want to put your files somewhere else, and feel free to do that if you’re comfortable with this process.) You’re going to click and drag the folders to the desktop; you should see a little “+ Copy to desktop” subtitle show up.
We’re going to move them somewhere more accessible – the desktop. (You may want to put your files somewhere else, and feel free to do that if you’re comfortable with this process.) You’re going to click and drag the folders to the desktop; you should see a little “+ Copy to desktop” subtitle show up.
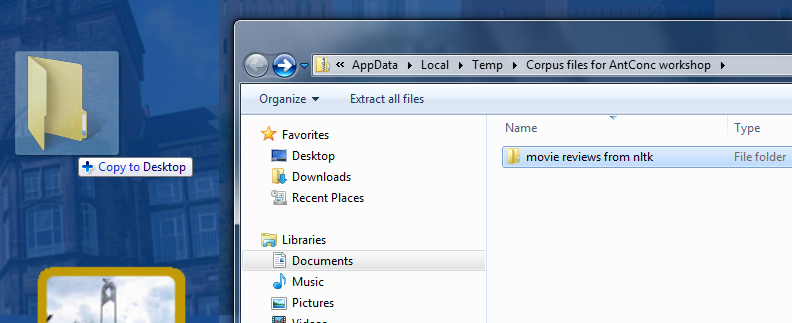
This might take a minute or two while the folder moves.
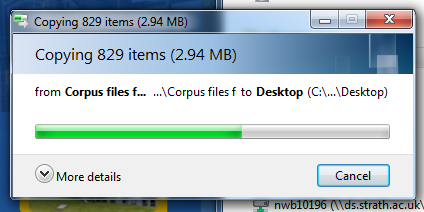
When this is complete, you should have your folder on the desktop:
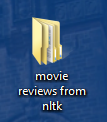
1.3 Getting AntConc
We’re going to use an older version of AntConc, version 3.2.4 today. You can also download the most recent version for whichever operating system you use from this page. The difference between these two versions is very small; we’re going to use the older version today because there are a few things it’s slightly better at for beginners. The differences are largely cosmetic, it must be said.
Today we’re going to download AntConc and run it (rather than install it). If you’ve ever tried to download software to a computer and discover you can’t, you may be familiar with the concept of user permissions. To sort of circumvent that issue we’re going to download the software and just run it, rather than install it to the computer directly.
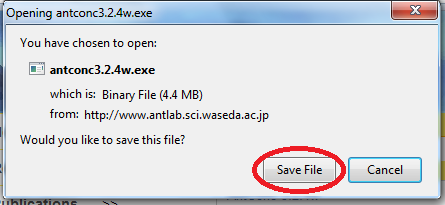
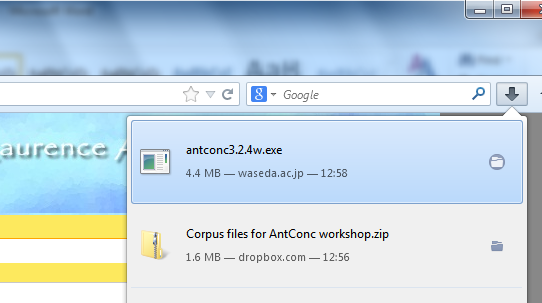
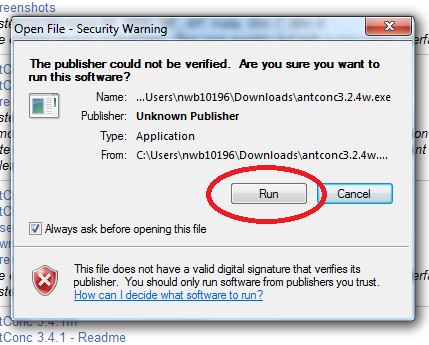
Please go to http://www.laurenceanthony.net/software/antconc/releases/AntConc324/ and download the file Antconc.exe (for PCs). Select Save File. On Internet Explorer, it will ask you if you want to RUN or SAVE the file. Select RUN, rather than Save File; it will go directly to the security warning below. On Firefox, select SAVE FILE, then RUN (see screenshots below)
You want to RUN the software, so click RUN on the security warning dialog box.
1.4 Getting Started
When AntConc launches, it will look like this. 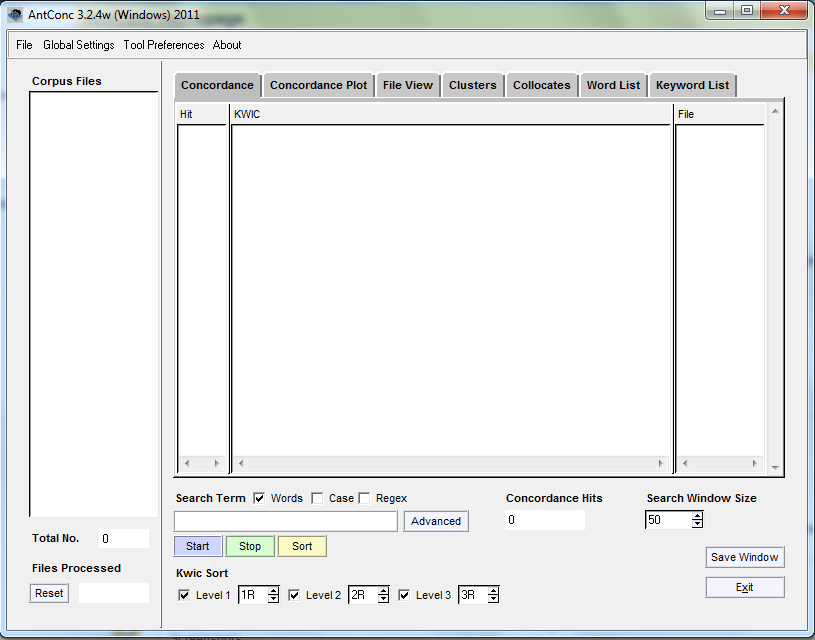
On the left-hand side, there is a window to see all corpus files loaded. We’ll look at that more fully in a second.
There are 7 tabs in the centre:
Concordance: This will show you what’s known as a Keyword in Context view (abbreviated KWIC, more on this in a minute), using the search bar below it
Concordance Plot: this will show you a very simple visualization of your KWIC search, where each instance will be represented as a little black line from beginning to end of each file containing the search term.
File View: This will show you a full file view for larger context of a result.
Clusters: This view shows you words which very frequently appear together.
Collocates: clusters show us words which definitely appear together in a corpus; collocates show words which are statistically likely to appear together.
Word list: All the words in your corpus.
Keyword List: This will show comparisons between two corpora.
This two hour workshop will barely scratch the surface of what you can do with AntConc. Today we’re going to address the Concordance, Collocates, and (very briefly) Keywords and Word List functions. I encourage you to look at the others on your own time.
Further help and resources are available, linked 1/3 of the way down on the software page, after Citing/Referencing AntConc. Here’s a selection –
- https://groups.google.com/forum/#!forum/antconc
- AntConc3.2.0 Help
- AntConc3.1.2 Help
- Various video tutorials (https://www.youtube.com/user/AntlabJPN)
- #corpusMOOC / https://www.futurelearn.com/courses/corpus-linguistics (running again September 2014)
1.5 Loading Corpora
Like opening a file elsewhere, we’re going to start with File > Open, but instead of opening just ONE file we want to open the directory of all our files.
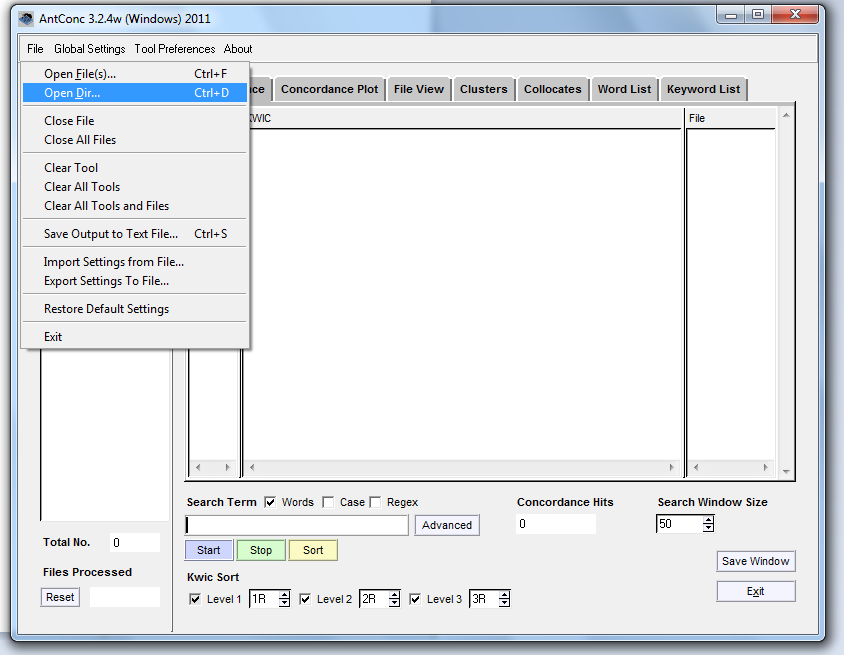
Remember we’ve put our files on the desktop, so navigate there in the dropdown menu.
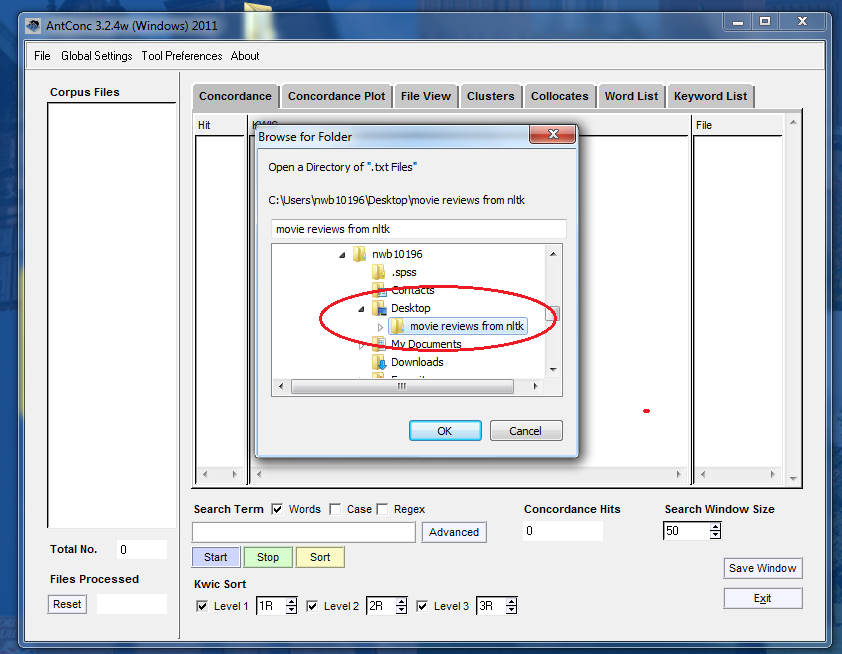
From the Desktop you want to navigate to our folder “movie reviews from nltk”:
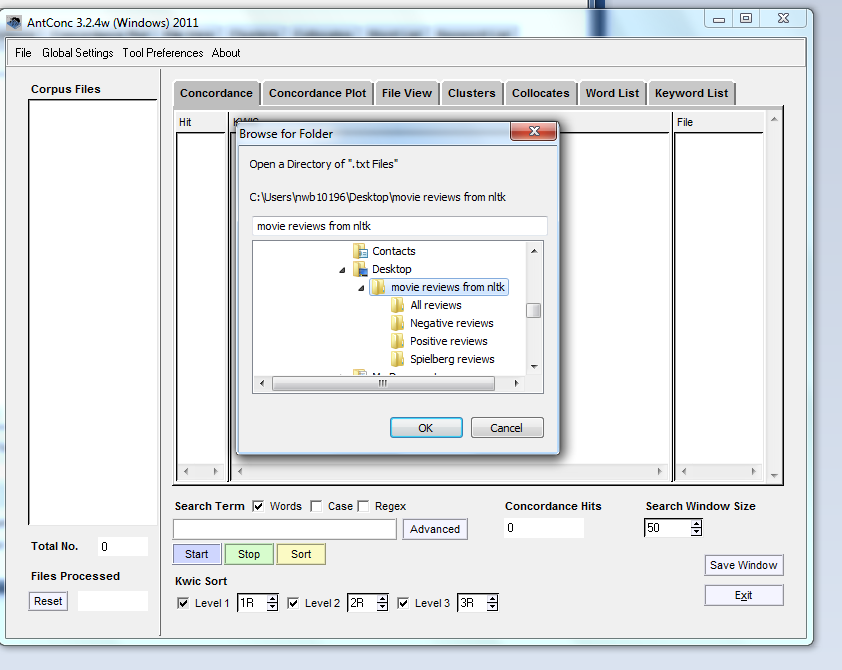
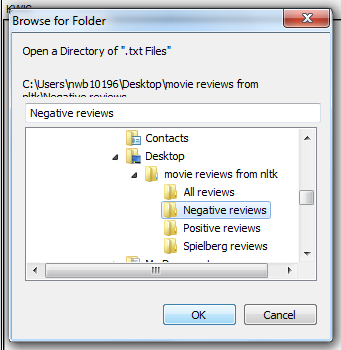
First you will select “Negative Reviews” and hit OK. 200 texts should load in the lefthand column Corpus Files – watch the Total No. box!
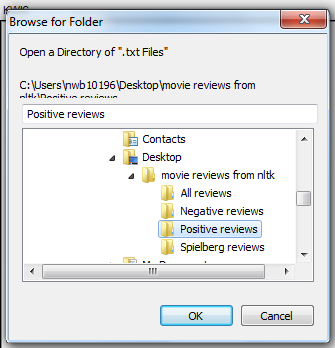
Then you’re going to repeat the process to load the folder “Positive Reviews”. You should now have 400 texts in the Corpus Files column.
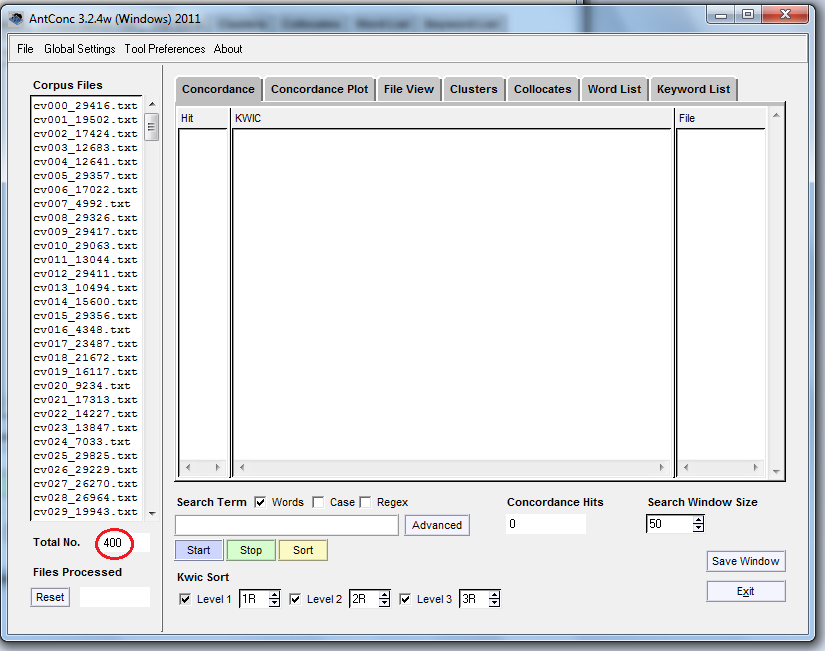
2 Basic analysis
2.1 Start with a basic search
In the search box at the bottom, type the and click “start”. The Concordance view will show you every time the word the appears in our corpus of movie reviews.

(14618 times, according to the Concordance Hits box in the bottom centre.)
One of the things corpus tools like Antconc are very good at are finding patterns in language. The KWIC view is a good way to start looking for patterns. Even though it’s still a lot of information, what kinds of words appear near the?
Try a similar search for a – do we get the same kinds of patterns?
Now that you’re comfortable with looking at a KWIC line, try doing it again with shot.
What do you see? I understand this can be a difficult to read way of identifiying patterns. Try pressing the yellow “sort” button. What happens now?

(This might be easier to read!)
2.2 Search Operators
* operator (zero or more characters) can help, for instance, find both the singular and the plural forms of nouns
Example: search for qualit*, then sort this search.
what tends to precede and follow quality & qualities?
For a full list of available wildcard operators and what they mean, go to Global Settings > Wildcard Settings.
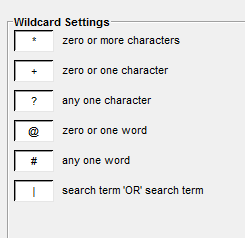
What’s the difference between * and ?
Search for th*n and th?n. What do these two search queries tell us?
More specifically: searching with the ? operator
wom?n – both women and woman
m?n – man and men, but also min
contrast to m*n: not helpful, because you’ll get mean, melon etc
➢ Task: compare these two searches: wom?n and m?n
First, sort each search in a meaningful way (eg. by search term then 1L then 2L)
Then File > Save output to text file (& append with .txt. HINT: you may want to give more information in your file name than just “antconc_results.txt”)
And now you can open the plain text file, which you might have to expand to make it readable:
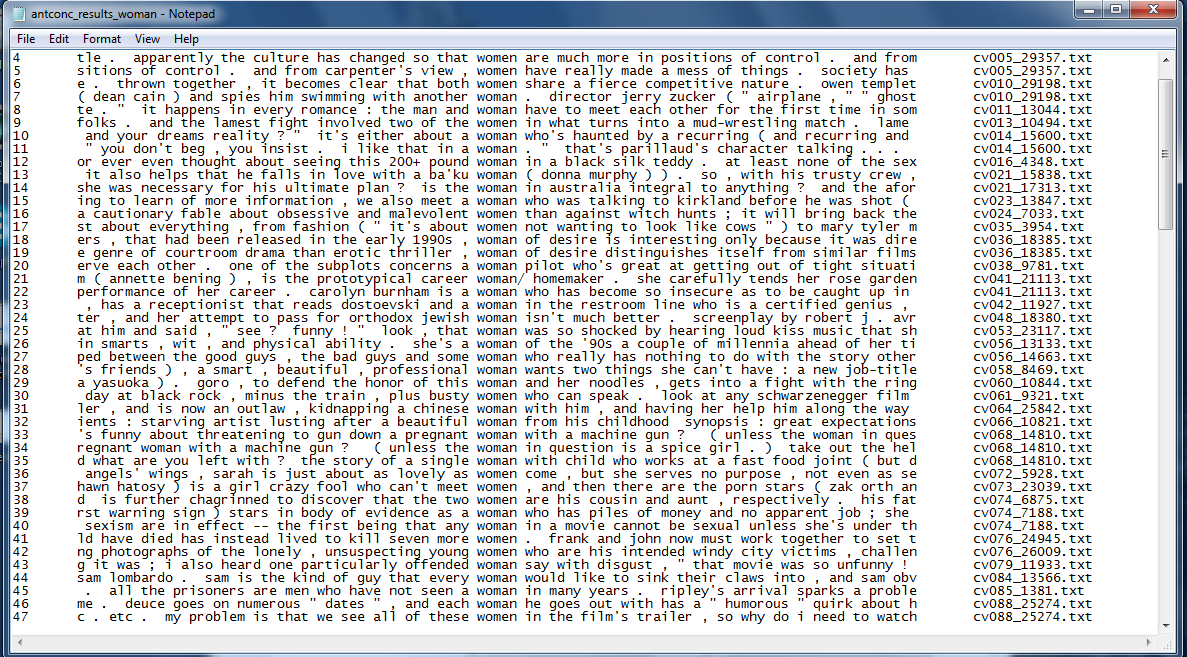
Do this for each of the two searches and then look at the two text files side by side.
What do you notice?
| operator (“or”):
Example: Search on she|he
Now search for these separately: how many instances of she vs he?
Many fewer instances of she – why? That’s a research question!
Sort the she|he search for patterns – do particular verbs follow each?
➢ Task: practice these skills on a search term of your own choice.
Practice searching a word of your choice, sorting in different ways, using wildcard(s), and finally exporting. Guiding focus question here: what kinds of patterns do you see?
3 Collocates and word lists
Having looked at the KWIC lines for patterns, don’t you wish there was a way for the computer to give you a list of words which appear most frequently in company with your keyword?
3.1 Collocates
There is: the Collocates tab. Click that, and AntConc will tell you it needs to create a word list. Hit OK, and it will do it automatically.
NOTE: You will only get this notice when you haven’t created a word list yet.
Try generating collocates for she.
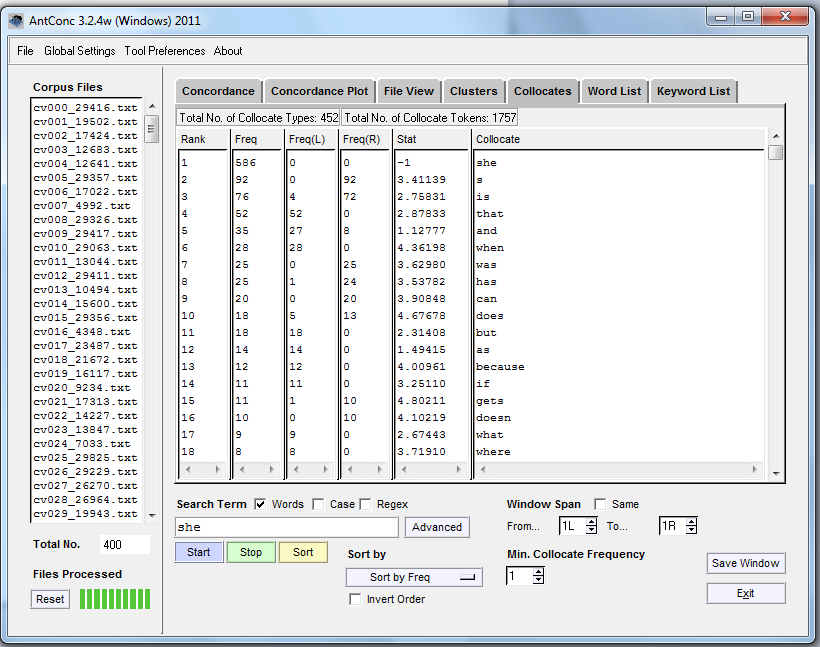
The unsorted results will seem to start with function words (words that build phrases) then go down to content words (words that build meaning)– these small boring words are the most frequent words in English (http://www.wordfrequency.info/free.asp?s=y), which are largely phrase builders.
Some people might want to remove these small words by using a stopword list. Personally I don’t encourage this practice because addressing highly-frequent words is where computers shine! As readers we tend not to notice them very much. Computers, especially software like Antconc, can show us where these words do and do not appear and that can be quite interesting, especially in very large collections of text.
➢ Task: generate collocates for m?n and wom?n. Now sort them by frequency to 1L.
This tells us about what makes a man or woman ‘movie-worthy’
– women have to be ‘beautiful’ or ‘pregnant’ or ‘sophisticated’
– men have to be somehow outside the norm – ‘holy’ or ‘black’ or ‘old’
This is not necessarily telling us about the movies but about the way those movies are written about in reviews, and can lead us to ask more nuanced questions, like “How are women in romantic comedies described in reviews written by men compared to those written by women?”
3.1 Making comparisons
Something we haven’t talked about explicitly is that the way your organize your files makes a difference to the kinds of questions you can ask and the kinds of results you will get.
Remember that we are comparing ‘negative’ and ‘positive’ reviews quite flatly here: we’ve loaded both of them into AntConc. You could, for instance, make comparisons of data, such as positive vs negative movie reviews. You can also make other comparisons using corpora:
- One director’s movie reviews vs movie reviews in general
- Movie reviews vs music reviews
- Movie reviews vs book reviews
- Positive movie reviews vs positive book reviews
- Positive movie reviews vs negative book reviews
- Movie reviews vs news articles about sport
- Movie reviews vs news articles in general
- Etc
Each of these comparisons will tell you something different, and can produce different research questions, such as:
- How are movie reviews different than other kinds of media reviews?
- How are movie reviews different than other kinds of published writing?
- How do movie reviews compare to other specific kinds of writing, such as sport writing?
- How do movie reviews have in common with music writing?
- Etc
And of course you could flip those questions to make further research questions:
- How are book reviews different to movie reviews?
- How are music reviews different than movie reviews?
- What do published newspaper articles have in common?
- How are movie reviews similar to other kinds of published writing?
And, of course, the files you put in your corpus will shape your results (again, the question of representativeness and sampling are highly relevant here – it’s not always necessary or even ideal to use ALL of a dataset, even if you do have it).
4 Comparing corpora
One of the most powerful types of analysis is comparing your corpus to a larger reference corpus.
We’ve pulled out reviews of movies with which Steven Spielberg is associated (as director or producer), & we can compare them to a reference corpus of movies by a range of directors.
Think carefully about what a reference corpus for your own research might look like (eg. a study of Agatha Christie’s language in her later years would work nicely as an analysis corpus for comparison to a reference corpus of all her novels). Remember, again, that corpus construction is a subfield in its own right.
Settings > Tool preferences > Keyword List
Under ‘Reference Corpus’ make sure Use raw files is checked
Add Directory > open the folder containing the files that make up the reference corpus
Ensure you have a whole list of files
Hit Load (& wait …) then once the ‘Loaded’ box is checked, hit Apply.
You can also opt to swap reference corpus & main files (SWAP REF/MAIN FILES) and it is worth looking at what both results show.
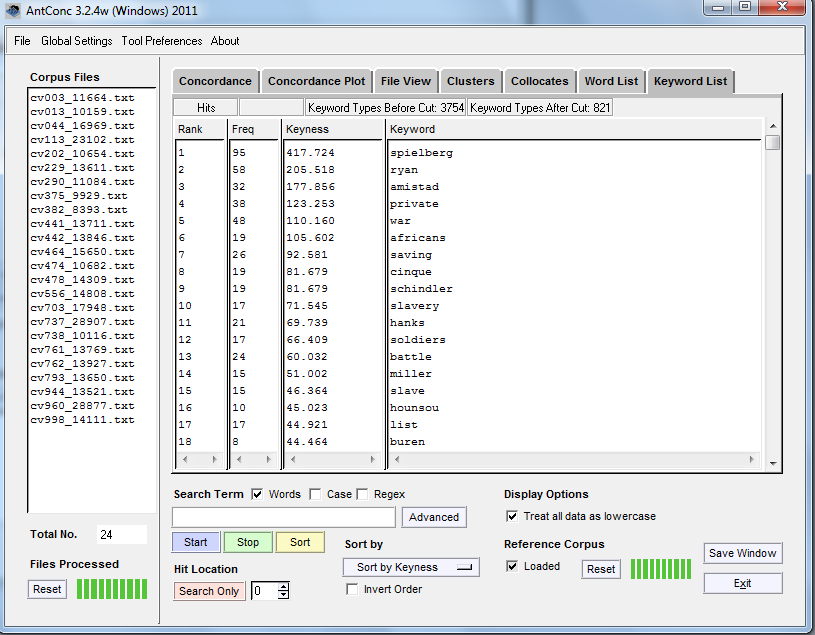
In Keyword List, just hit Start (with nothing typed in the search box)
We see a list of Keywords that have words that are much more ‘unusual’ – more statistically unexpected – in the corpus we are looking at when compared to the reference corpus.
> Keyness: this is the frequency of a word in the text when compared with its frequency in a reference corpus, “such that the statistical probability as computed by an appropriate procedure is smaller than or equal to a p value specified by the user.” – taken from here.)
For those interested in the statistical details, see the section on keyness on p7 of Laurence Anthony’s readme file (http://www.antlab.sci.waseda.ac.jp/software/antconc335/AntConc_readme.pdf).
What are our keywords?
5 Discussion
Things to think about:
- Why you might want to compare two corpora
- What kinds of queries make meaningful research questions
- Principles of corpora construction: sampling & ensure you can get something representative
6 Further Resources (cross-posted here)
This is a short bibliography meant to get you started in corpus linguistics – it is by no means comprehensive, but should serve to be a good introductory overview of the field.
6.1 Books (and one article)
Baker, Paul, Andrew Hardie and Tony McEnery. (2006). A Glossary of Corpus Linguistics. Edinburgh, Edinburgh UP.
Biber, Douglas (1993). “Representativeness in Corpus Design”. Literary and Linguistic Computing, 8 (4): 243-257. http://llc.oxfordjournals.org/content/8/4/243.abstract
Biber, Douglas, Susan Conrad and Randi Reppen (1998). Corpus Linguistics: Investigating Language Structure and Use. Cambridge: Cambridge UP.
Granger, Sylviane, Joseph Hung and Stephanie Peych-Tyson. (2002). Computer Learner Corpora, Second Language Acquisition and Foreign Language Teaching. Amsterdam: John Benjamins.
Hoey, Michael, Michaela Stubbs, Michaela Mahlberg, and Wolfgang Teubert. (2011). Text, Discourse and Corpora. London: Continuum.
Hunston, S. (2002). Corpora in applied linguistics. Cambridge: Cambridge University Press.
Mahlberg, Michaela. (2013). Corpus Stylistics and Dickens’ Fiction. London: Routledge.
McEnery, T. and Hardie, A. (2012). Corpus Linguistics: Method, theory and practice. Cambridge: Cambridge UP.
O’Keefe, Anne and Michael McCarthy, eds. (2010). The Routledge Handbook of Corpus Linguistics. London: Routledge.
Sinclair, John and Ronald Carter. (2004). Trust the Text. London: Routledge.
Sinclair, John. (1991) Corpus Concordance Collocation. Oxford: Oxford UP.
Wynne, M (ed.) (2005). Developing Linguistic Corpora: a Guide to Good Practice. Oxford: Oxbow Books. http://www.ahds.ac.uk/creating/guides/linguistic-corpora/
6.2 Scholarly Journals
Corpora http://www.euppublishing.com/journal/cor
ICAME http://icame.uib.no/journal.html
ICJL https://benjamins.com/#catalog/journals/ijcl
Literary and Linguistic Computing http://llc.oxfordjournals.org/
6.3 Externally compiled bibliographies and resources
David Lee’s Bookmarks for corpus-based linguistics http://www.uow.edu.au/~dlee/CBLLinks.htm
Costas Gabrielatos has been compiling a bibliography of Critical Discourse Analysis using corpora, 1982-present http://www.gabrielatos.com/CLDA-Biblio.htm
Members of the corpus linguistics working group UCREL at Lancaster University have compiled some of their many publications here http://ucrel.lancs.ac.uk/pubs.html; see also their LINKS page http://ucrel.lancs.ac.uk/links.html
Michaela Mahlberg is one of the leading figures in corpus stylistics (especially of interest if you want to work on literary texts) http://www.michaelamahlberg.com/publications.shtml; in 2006 she helped compile a corpus stylistics bibliography (pdf) with Martin Wynne.
Lots of work is done on Second Language Acquisition using learner corpora. Here’s a compendium of learner corpora http://www.uclouvain.be/en-cecl-lcworld.html
Corpora-List (mailing list) http://torvald.aksis.uib.no/corpora/
CorpusMOOC https://www.futurelearn.com/courses/corpus-linguistics, run out of Lancaster University, is an amazingly thorough resource. Even if you can’t do everything in their course, there’s lots of step-by-step how-tos, videos, notes, readings, and help available for everyone from experts to absolute beginners.
6.4 Compiled Corpora
Xiao, Z. (2009). Well-Known and Influential Corpora, A Survey http://www.lancaster.ac.uk/staff/xiaoz/papers/corpus%20survey.htm, based on Xiao (2009), “Theory-driven corpus research: using corpora to inform aspect theory”. In A. Lüdeling & M. Kyto (eds) Corpus Linguistics: An International Handbook [Volume 2]. Berlin: Mouton de Gruyter. 987-1007.
Various Historical Corpora http://www.helsinki.fi/varieng/CoRD/corpora/index.html
Oxford Text Archive http://ota.ahds.ac.uk/
Linguistic Data Consortium http://catalog.ldc.upenn.edu/
CQPWeb, a front end to various corpora https://cqpweb.lancs.ac.uk/
BYU Corpora http://corpus.byu.edu/
NLTK Corpora http://nltk.googlecode.com/svn/trunk/nltk_data/index.xml
6.5 DIY Corpora (some work required)
Project Gutenberg http://gutenberg.org
LexisNexis Newspapers https://www.lexisnexis.com/uk/nexis/
LexisNexis Law https://www.lexisnexis.com/uk/legal
6.6 Other Concordance software
No one software is better than another, though some are better at certain things than others. Much here comes down to personal taste, much like Firefox vs Chrome or Android vs iPhone. AntConc is great but it is far from the only software available. (Note that these may require a licencing fee.)
AntConc http://www.antlab.sci.waseda.ac.jp/software.html
Wordsmith http://lexically.net/
Monoconc http://www.monoconc.com/
CasualConc https://sites.google.com/site/casualconc/
Wmatrix http://ucrel.lancs.ac.uk/wmatrix/
SketchEngine http://www.sketchengine.co.uk/
R http://www.rstudio.com/ide/docs/using/source (for the advanced user)
Anthony, Laurence. (2013). “A critical look at software tools in corpus linguistics.” Linguistic Research 30(2), 141-161.
6.7 Annotation
You may want to annotate your corpus for certain features, such as author, location, specific discourse markers, parts of speech, transcription, etc.
Some of the compiled corpora might come with included annotation.
Text Encoding Initiative http://www.tei-c.org/index.xml
A Gentle Introduction to XML http://www.tei-c.org/release/doc/tei-p5-doc/en/html/SG.html
Hardie, A (2014) “Modest XML for Corpora: Not a standard, but a suggestion”. ICAME Journal 38: 73-103.
UAM Corpus Tool does both concordance work and annotation http://www.wagsoft.com/CorpusTool/
6.7.1 Linguistic Annotation
Natural Language Toolkit http://nltk.org & the NLTK book http://www.nltk.org/book/ch01.html
Stanford NLP Parser http://nlp.stanford.edu/software/corenlp.shtml
(includes Named Entity Recognition, semantic parser, and grammatical part-of-speech tagging)
CLAWS, a part of speech tagger http://ucrel.lancs.ac.uk/claws/
USAS, a semantic tagger http://ucrel.lancs.ac.uk/usas/
6.8 Statistics Help
6.8.1 Not Advanced
Wikipedia http://wikipedia.com (great for advanced concepts written for the non-mathy type)
Log Likelihood, explained http://ucrel.lancs.ac.uk/llwizard.html
AntConc Videos https://www.youtube.com/user/AntlabJPN
WordSmith Getting Started Files http://www.lexically.net/downloads/version6/HTML/index.html?getting_started.htm
Oakes, M. (1998): Statistics for Corpus Linguistics. Edinburgh: Edinburgh University Press.
Baroni, M. and S. Evert. (2009): “Statistical methods for corpus exploitation”, in A. Lüdeling and M. Kytö (eds.), Corpus Linguistics: An International Handbook Vol. 2. Berlin: de Gruyter. 777-803.
6.8.2 Advanced
Stefan Th. Gries’ publications: http://www.linguistics.ucsb.edu/faculty/stgries/research/overview-research.html
Baayen, R.H. (2008). Analyzing Linguistic Data: A Practical Introduction to Statistics Using R. Cambridge: Cambridge University Press.
heather froehlich // last updated 27 July 2015

NICE cheers heather,
i don’t mean to spam and hope u can indulge me! i have written some guides your readers may be interested in (aimed at language teachers but has broad interest as well imo)
first one in series is here (would complement your post as this one looks at compiling a corpus from web)- http://eflnotes.wordpress.com/2013/03/06/building-your-own-corpus-textstat-antconc/
also a video for those who might prefer this mode – http://youtu.be/CWsAD5TnnMI?t=1m12s
thanks
mura