I continue to watch the rise of artificial intelligence in every corner of our lives with great interest … and realized very quickly that for lots of people, “AI” is one big scary umbrella of confusing, mysterious processes that suddenly emerged out of basically nowhere. Except that it hadn’t… if you had been following computational approaches to information retrieval, human-computer interaction, natural language processing, or any of the many intersections of these fields. But if you understandably weren’t paying a ton of attention to these spaces – for any reason – this seems like brand-new, terrifying levels of information. And in order to catch up, the cliff seems steep.
As longtime readers of this space know, I have worked at the intersection of computer science and humanities research since approximately 2012. But I am not a computer scientist or mathematician; I just play one on TV. I have degrees in English language and literature, and I came in to this space with approximately zero mathematical or computational knowledge. Meanwhile, many of the trainings I have seen and attended have assume a certain threshold of knowledge about the latest in very advanced computational research. Showing a flowchart and saying “This is the model for [whatever]” is a surefire way to make most people feel daunted and afraid to ask more questions. For the past year, I’ve listened and watched with some concerns.
In this past year I rapidly realized that for plenty of people, “AI” is a blanket term for “generative AI”, which isn’t true. As the University of Arizona began to ramp up their AI literacy efforts in the spring, I agreed to put together a training that assumes no prior math, computer science, or any of the scary things that come up when we talk about AI. I was as normie-humanities as they came, until someone gave me a computer and said “figure it out”! So I feel comfortable saying that if I can learn it, you can learn it too. This training assumes zero prior knowledge and covers the following topics:
- Discussion of 2 key kinds of AI (generative and machine learning approaches)
- Foundational concepts required for understanding the big-umbrella of AI
- Ways we can assess AI content
This training was developed with the audience of employees at the University of Arizona Libraries in Tucson, Arizona in mind. I am sharing these slides and resources using a CC-BY-NC license with the expectation that you will want to adjust some of the content to reflect your current location/situation, especially in slides 13, 14, and 22-26, but others are fair game as well (such is the joy of a CC-BY license).
View and download the whole presentation as a .pptx file from Dropbox here. My notes do not appear to render in the preview provided by Dropbox, so you will have to download this file to your computer and open it in PowerPoint from there to get the most out of this content.
FAQS about this presentation
Q: All AI is evil, ruining our lives, and anything that suggests otherwise is also evil.
A: I wanted to focus on making it clear that not all AI is totally evil, and that some of it is actually very familiar to us. Generative models have gained prominence but actually there is quite a lot of AI that we can like! This training tries to take a critical view of what is/is not possible in the large umbrella of AI, and has the end goal of helping us critically engage with why outputs can look the way they do.
Q: I am a self-professed AI pro and I think your presentation is too simplistic.
A: Thanks for your input! I’m glad you are comfortable with this content, but I’ve learned that not everyone is. My philosophy is even if you know the basics of probability in the early slides, starting there puts everyone on an even playing field when we get to the more complicated stuff. Remember that not everyone knows all the things you do, and hopefully, there’s something for everyone in these slides.
Q: Who is this for, anyway?
A: I wrote this with librarians (both faculty/staff) in mind, with the goal of covering the key principles of AI literacy someone needs to understand before diving deeper into specific products. I think it has the capacity to translate pretty well into other disciplinary spaces/domains.
Q: Why didn’t you talk about ChatGPT or Claude or Gemini?
A: I wanted to remain platform-agnostic and instead talk about the underlying technologies that make these platforms possible. They all run on various implementations of the ideas presented here. Plus, platforms change rapidly and what is true right now (March 2026) may not be the same by the time you are encountering this content.
Q: What about tools like Elicit or Perplexity?
A: See the answer to the above question. Stuff changes fast! It’s hard to speak to exact outcomes.
Q: What’s RAG and MCP? Why didn’t you include them in this presentation?
A: RAG (Retrieval-augmented generation) and MCP (Model Context Protocols) are more advanced ways of interacting with generative AI systems. This page on Model Context Protocols is particularly accessible if you know what an API is. The Wikipedia page for RAG is also relatively manageable, and links out to more complex concepts. These are not essential for understanding what is going on under the hood of artificial intelligence more broadly. I may develop a future training on understanding different kinds of generative models for information-retrieval (RAG, semantic searching, etc) but no promises.
Q: How long does this presentation typically take to do live?
A: I budget 90 minutes for this — barring lots of questions at the beginning (I take some pauses to make sure people are all on the same page as me on the preliminary stuff, following the Carpentries instructor training model of ‘preparing to teach’)
I typically can cover the slides in about 60 minutes and can take questions for the next 30. Your mileage may vary!
Q: What do you have against vector space? It should be included here.
A: I agree! I really wanted to include a whole discussion on vector space but I did not want to make this training last a minimum of 3 hours, which is what it would have been if I let myself do that. I find that there is already enough overwhelm in this topic, before we get into linear algebra for the masses. That said….there are ways to sneak in content about vector space, particularly in slides 19-22, if that is something you want to do. I also anticipate that a question will come up that will allow you to discuss vector space in a low-stakes way in the q&a.
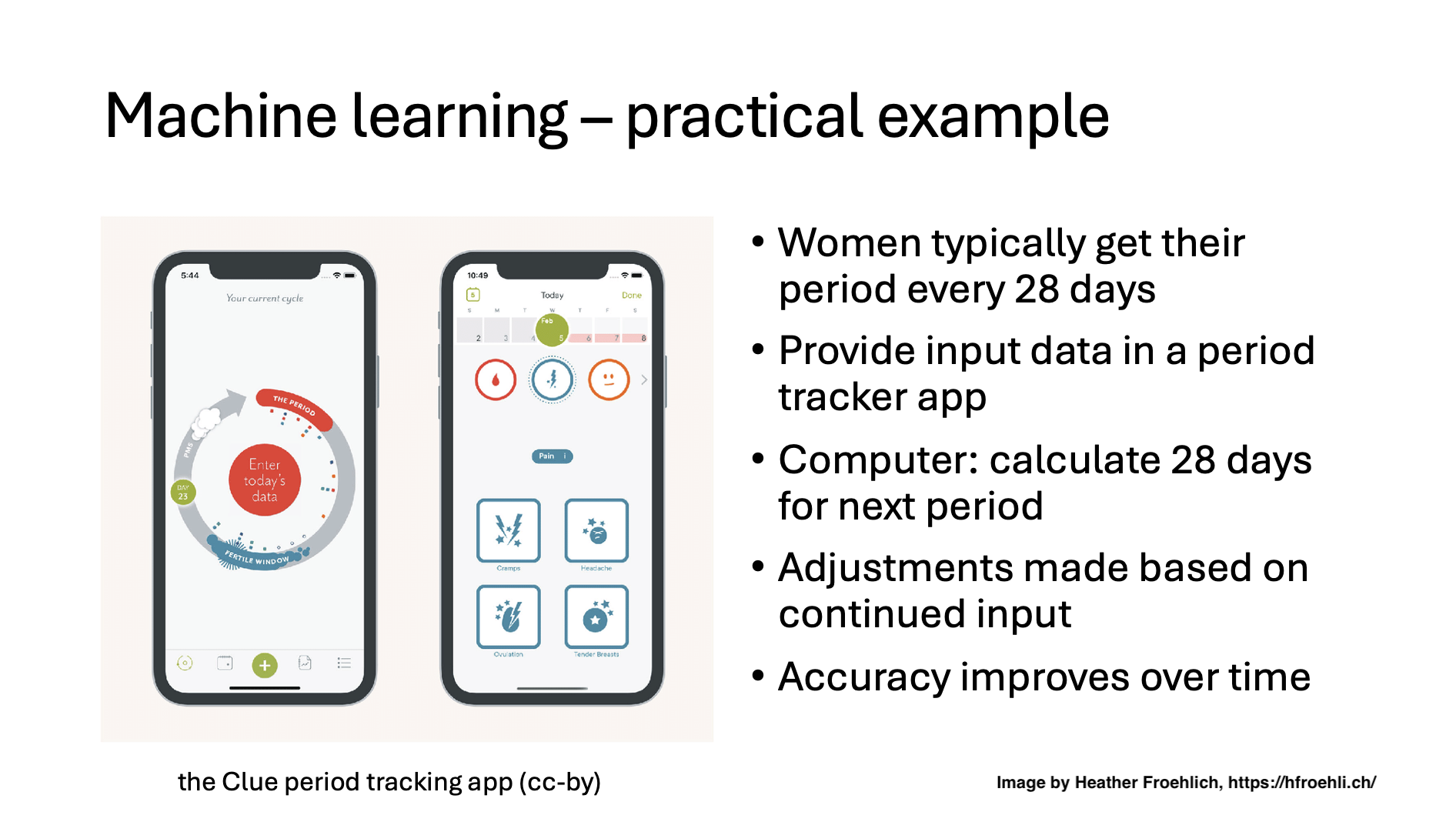
Q: I am mad about the gendered implications about menstrual trackers. Clue is very good about not being gendered!!
A: I understand. I am not trying to be gender essentialist! I wanted to focus on the implications of machine learning versus generative approaches to period tracking in visual format that was manageble to read and listen to. If you don’t like what I’ve done, please feel adjust these slides for yourself!
Q: I would like to share these with my department, colleagues, friends. Can I do that?
A: Yes please! Please share this page with them, and cite me if you use them in other places. This material is shared using a CC-BY-NC license to encourage reuse. Here’s a link to learn more about Creative Commons licenses.
Q: I want to take your feedback survey, can I do that?
A: Sure! You can fill it out at this link: https://forms.gle/RkQ2XqN1dMx7Z1LTA. We may/may not use your feedback.
Q: This was really helpful. Do you have other trainings like this?
A: Yes, I have a training for introducing novices to Excel and spreadsheets more generally that may be of interest to you as well.








You must be logged in to post a comment.