I was given a corpus of 400 plays for my PhD on gender in Early Modern London plays. Up to this point I had previously been focusing largely on Shakespeare, but have recently been moving into the larger corpus. So what does one do with 400 plays? My solution was “get to know them a little bit.” I was counting the raw frequencies for lord/lady, man/wom*n, and knave/wench in the entire corpus using AntConc, manually recording it, and then transcribing this data into a spreadsheet. I had selected these terms on the basis that I had recently spent a lot of time looking at likely collocates for these terms, as these binaries represent a high-, neutral-, and low- formality distinction.
Several of my twitter followers asked why I was just looking at wom*n and not also m*n, and the answer is that without a regular expression I was going to get a fair quantity of noise from m*n (including but certainly not limited to man, men, mean, moon, maiden, maintain, morn, mutton…). Wom*n, I had found, was a highly successful use of a wildcard, only picking up woman and women in the corpus. While this category remains somewhat imbalanced, it presents a pretty clear scope of the quantities for more neutral forms. Now that I have a better sense of what my corpus is like beyond “those files in that folder on my computer”, I can always go back and get other information pretty easily.
What can we learn from a corpus of 400 plays?
For starters, there’s not actually 400 plays in the 400-play-corpus, but 325 plays. I knew when I started this project that this corpus was less than 400, and that it did not cover everything. It is a representative corpus, but I was a bit surprised at how much less than 400 plays I actually had. These 325 plays cover 53 individual authors from the years 1514-1662,* which looks like this:
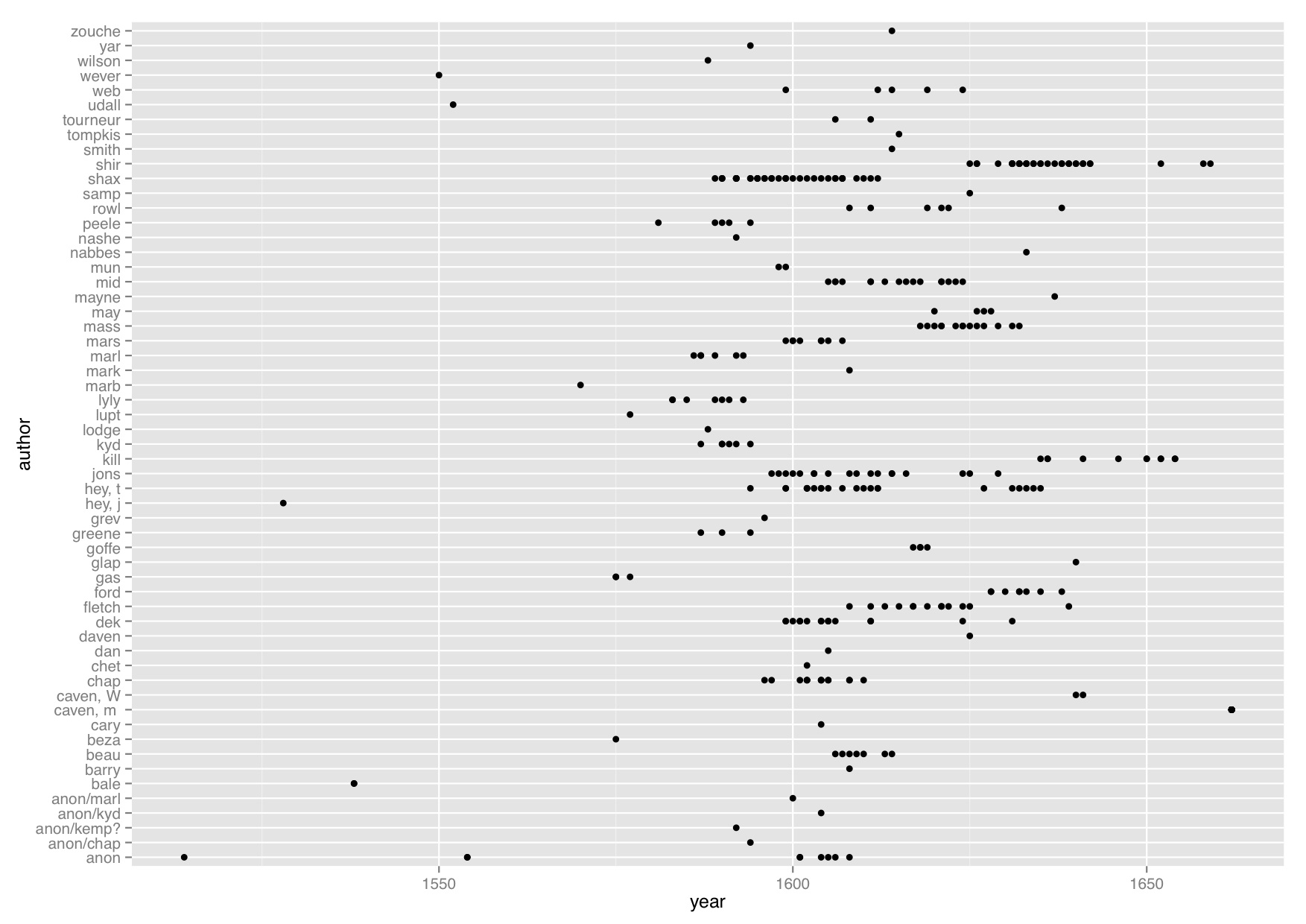
Each dot represents a year of publication. You will note that some authors are more represented than others (Shirley, for example, has 33 plays in the corpus, spanning a number of years, whereas someone like Beza has only one play in the corpus.) The average year for a play to be published was in 1613, and an overwhelming majority of these plays have been published in the late 1500s into the first half of the 1600s.
Once I had the raw frequencies for everything, I was curious to see how these terms performed diachronically. For ease I’m going to keep calling it the 400-play corpus, and as you’re reading, remember that this is very quick & dirty. There’s a lot more to say & do with this data, but I think talking about raw data is a useful endeavor in that speaks volumes about the sample itself.


These graphs suggest that the use of lady and wom*n look more frequent in the corpus from the late 1500s onwards (they’re both almost in a parabola shape) whereas the use of lord and man begins to decline around 1600, creating more of a bell curve effect.
And what about knave and wench? We see there’s a distinct decrease in usage for both just after the early 1600s, though knave was more frequent earlier in the corpus:
Two of these three sets of binaries show very similar graphs, but that’s because this is raw data: there’s simply more instances of plays occurring around the late 1530s onwards.
This was my first time using R for any graphing ever, so I’m going to dive back in and see what I can do with a more normalized corpus next.
—
Additionally, I owe a great debt to the following people, who were very selfless and helpful:
Sarah Werner, Julia Flanders, Shawn Moore, Douglas Clark, Simon Davies. Thank you.

One comment
Comments are closed.