This past week I was talking about the relationships between corpus linguistics and digital humanities as a visiting scholar at VARIENG, a very well known historical sociolinguistics and corpus linguistics working group. Corpus linguistics is a very text-oriented approach to language data, with much interest in curation, collection, annotation, and analysis – all things of much concern to digital humanists. If corpus linguistics is primarily concerned with text, digital humanities can be argued to be primarily be concerned about images: how to visualize textual information in a way that helps the user understand and interact with large data sets.
VARIENG has been compiling the Corpus of Early English Correspondence (CEEC) for a number of years, and one of their primary concerns is ‘what else can we do with all this metadata we’ve created’? Together, we discussed three main themes of corpus linguistics and digital humanities: access, ability, and the role of supplementary vs created knowledge. Digital humanities runs on a form of knowledge exchange, but this raises questions of who knows what, how, and how to access them.
Approaching a computer scientist with a bunch of historical letters may raise some “so what” eyebrows, but likewise, a computer scientist approaching a linguist with a software package to pull out lexical relationships might raise similar “so what” eyebrows: why should we care about your work and what can we do with it? Because both groups walk in with very different kinds of expertise, one of the very big challenges of digital work is to be able to reach a common language between the disciplines: both have very established, very theoretically-embedded systems of working.
All of this is to say that the takeaway factor for corpus linguistics research, and indeed any kind of digitally-inflected project, is very high. As Matti Rissanen says, and rightly so, “research begins when counting ends”. The so-what factor of counting requires heavy contextualization, human brainpower, time, funding, systems and communication – and none of these features are unique to corpus linguistics. Digitally-inflected scholarship requires complementary expertise in techniques, working and interacting with data; we need humanistic questions which can be pushed further with digital methods, not digital methods which (we hope) will push humanistic questions further. While it is nice to show what we already understand by condensing lots of information into a pretty picture, there are deeper questions to ask. If digital humanities currently serves mostly to supplement knowledge, rather than create new knowledge, we need to start thinking forward to ask “What else can we do with this data we’ve been curating?”
One thing we can do with this data is view it in new tools and learn to ask different questions, as we did with Docuscope, a rhetorical analysis software developed at Carnegie Mellon University.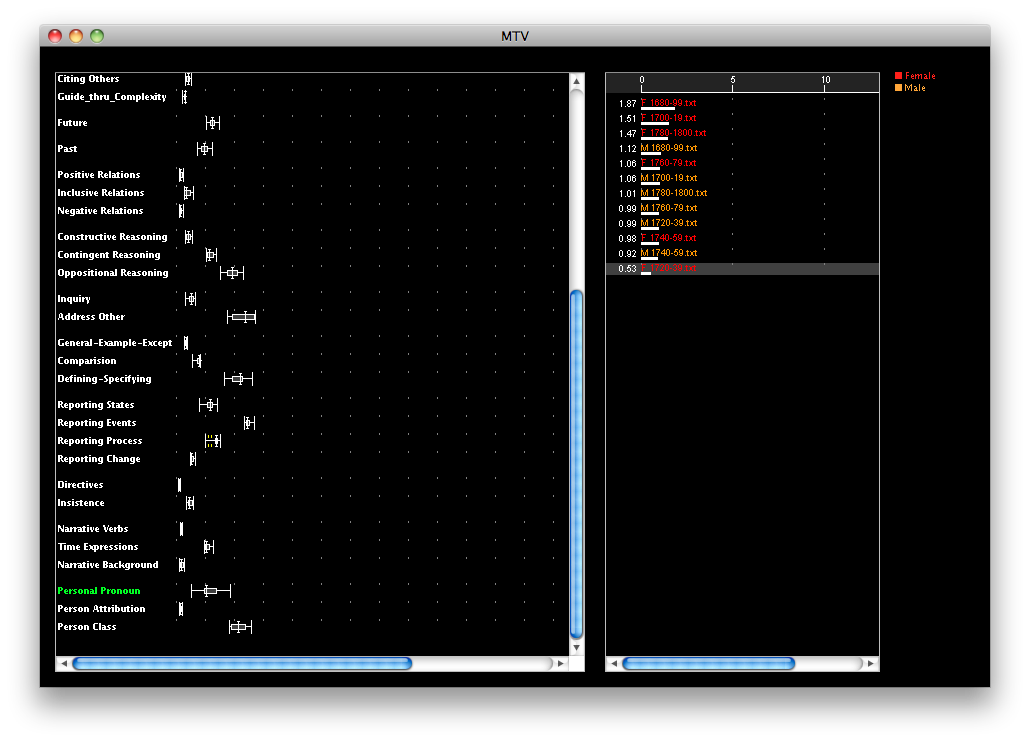
 Digital tools and techniques are question-making machines, not answer-providing packages. Here we may ask ourselves why F_1720-39.txt has a low count of Personal Pronouns in Docuscope, and the answer may be that what we consider to be personal pronouns (grammatically) are categorized otherwise by Docuscope and that other constructions are used instead. This isn’t magic and this can’t be quiet handwaving: we should be pushing ourselves towards asking questions which were previously impossible at the scale of sentence-level or lexical-level of detail, because suddenly we can.
Digital tools and techniques are question-making machines, not answer-providing packages. Here we may ask ourselves why F_1720-39.txt has a low count of Personal Pronouns in Docuscope, and the answer may be that what we consider to be personal pronouns (grammatically) are categorized otherwise by Docuscope and that other constructions are used instead. This isn’t magic and this can’t be quiet handwaving: we should be pushing ourselves towards asking questions which were previously impossible at the scale of sentence-level or lexical-level of detail, because suddenly we can.
Resources:
Slides from last week’s workshops (right-click to save as pdf files):
- Day one: What is digital humanities?
- Blogpost by Timo Honkela, summarizing Day 1
- Day two: What do you do with millions of words?
- Day three: Projects
