In my previous post I addressed how to produce a view of many concordance plots at once, and presented concordance plots for twelve vocatives which are indicative of social class in Shakespeare and a larger reference corpus of Early Modern Drama.
After double-checking all the concordance plot files using a hand-numbered master sheet, I normalised the files using the command convert plot*.jpg -size 415x47! plot*.jpg (on the off chance that any files weren’t ultimately the same size), created a new folder of the normalised files, and pulled out the examples which matched the numbers I had for Shakespeare’s plays for further analysis. I hadn’t addressed titles, as I wasn’t really aiming to look at individual authors, so each file is named plot1, plot2, plot234, etc. I went on to compile the results for these plays, felt confident about the fact that I had isolated Shakespeare, and wrote up my previous blog post.
This morning I had a nagging thought: What if those weren’t Shakespeare’s plays? After all, I had broken my #1 rule about using computational methods – assuming that everything at every step of the process worked the way I thought it did. I am probably a self-parodying pendant when it comes to computational methods, because when something goes wrong at some stage in the coding process it may *never* be visible or even noticed in the final output, and this gives me reason to seriously distrust automated processes for analysis.
Ultimately, I decided I would double-check the plays I had deemed to be “Shakespeare”’s. Even though I hadn’t done much automated processing with the image files, I had assumed that the normalisation process would only change the file names to represent a modified version: so that plot10 would become plot0-10, plot 11 would become plot0-11, plot234 would become plot0-234. I had assumed the information in these files wouldn’t change, and the names would correspond to the original files.
This was not true. Instead, I had isolated a very nice sample of 36 plays which I thought matched Shakespeare’s plays in numbering, but turned out to be sampled from throughout the corpus. Matching the sampled “Shakespeare” concordance plots to the master document of concordance plots, I found that I had at least one Middleton play and at least one Seneca play in addition to some (but not all) Shakespeare plays.[1] At this point I was worried, so I re-created Shakespeare’s concordance plots from the master document of concordance plots. By redoing the concordance plots, I could guarantee that these were at least all Shakespeare’s plays in the first instance. Then I normalised them again for size, and went back to see what happens in that process. The first files were a perfect match, as I had hoped. But once I moved to the second concordance plot, I was in trouble.
Below is an image showing the unmodified concordance plot for The Taming of the Shrew (shx2), outlined in red and on the top left-hand side.The other eight concordance plots in this image are normalised for size, and even without great detail you can tell that none of these match the original file. You don’t even need to see the whole image to see this:
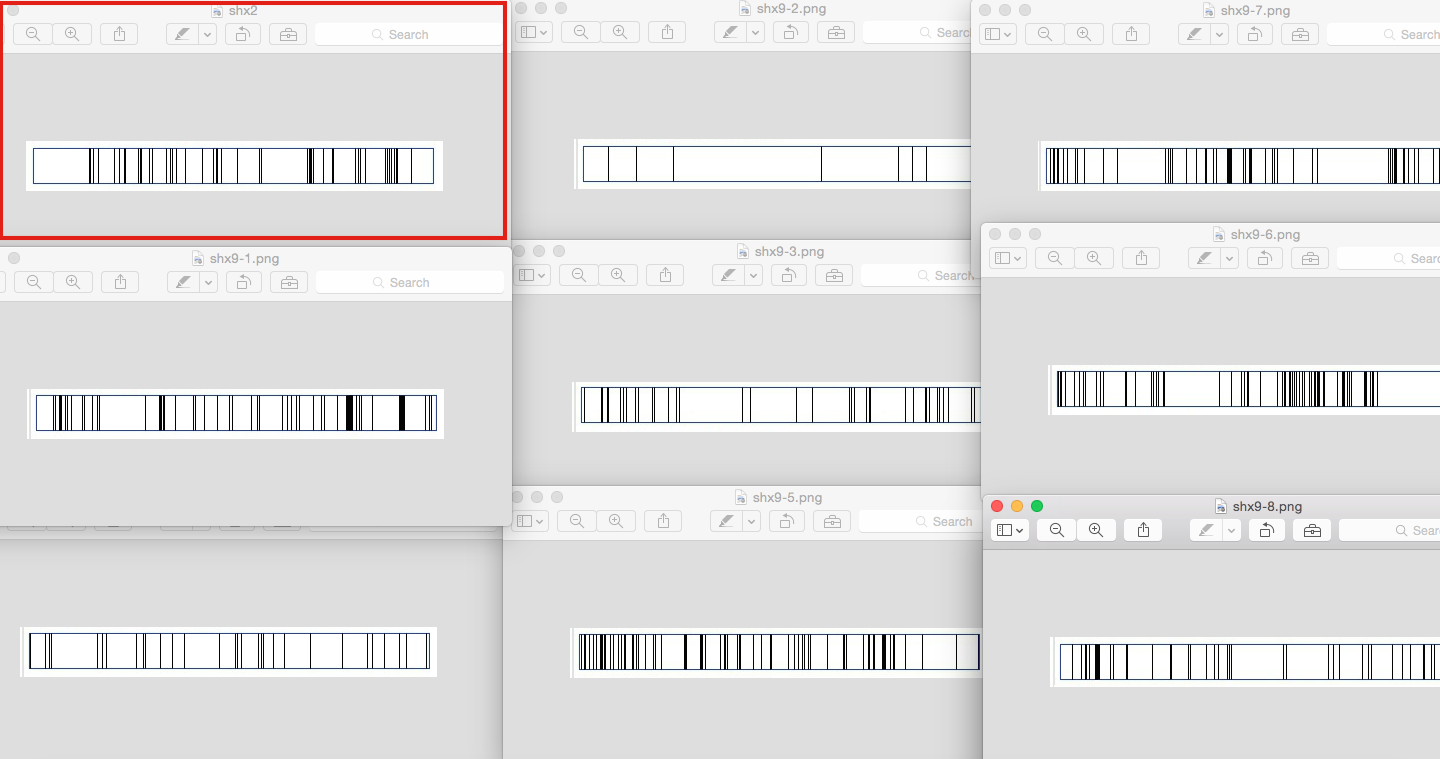
In other words, as I had suspected, the names of the normalised files didn’t correspond to the original file names, though they were all there.[2] More worryingly, I hadn’t caught it because I had assumed that the files were fine after running a process on them. The files produced results, and if I hadn’t double-checked (really, at this point, triple-checked), I wouldn’t have caught this discrepancy.
So what do concordance plots for Shakespeare’s plays look like in composite for the vocatives attached to a name in a bigram (reminder of search terms: lord [A-Z]|sir [A-Z]|master [A-Z]|duke [A-Z]|earl [A-Z]|king [A-Z]|signior [A-Z]|lady [A-Z]|mistress [A-Z]|madam [A-Z]|queen [A-Z]|dame [A-Z]) look like? Well, surprisingly, not so different from the sample curated previously, which may be less indicative of a specific authorial style:

Remember, we read these from left to right; now there’s a lot of use of vocatives in the very beginning of the plays, which stay quite strong near the rising action until there’s a relative absence just before and around the climax and the start of the falling action. Curiously, the heavy double hit || towards the end is still very visible, as well as a few more dark lines leading up to the conclusion. In some ways, the absence of these vocatives is almost more consistent, and therefore the white bits are more visible.
In the meantime I’m having a fascinating discussion with Lauren Ackerman about how to best address pixel density and depth of detail (especially in the larger EM play corpus), so maybe there will be a third instalment of concordance plots in the future.
[1] Seneca’s plays were published in the 1550s and 1560s, which is why they are included in this data set of printed plays in Early Modern London.
[2] The benefits of working with a smaller set like this means that there are are much smaller, finite number of texts to address: rather than n = 332332 possible combinations, I was now only looking at a possibility of n = 3636. So that was an improvement. In case you’re wondering what happened to one play, because previously I had claimed there were 37 Shakespeare plays, one play doesn’t have any instances of the vocatives being addressed in a bigram with a capital letter.




You must be logged in to post a comment.