[This is the text, more or less, of a paper I presented to the audience of the Scottish Digital Humanities Network’s “Getting Started In Digital Humanities” meeting in Edinburgh on 9 June 2014. You can view my slides here (pdf)]
Computers help me ask questions in ways that are much more difficult to achieve as a reader. This may sound obvious: reading a full corpus of plays, or really any text, takes time, and by the time I closely read all of them, I will have either have not noticed the minutae of all the texts or I will not have remembered some of them. Here, for example, is J. O. Halliwell-Phillipp’s The Works of William Shakespeare; the Text Formed from a New Collation of the Early Editions: to which are Added, All the Original Novels and Tales, on which the Plays are Founded; Copious Archæological Annotations on Each Play; an Essay on the Formation of the Text: and a Life of the Poet, which takes up quite a bit of space on a shelf:
This isn’t a criticism, nor is it an excuse for not reading; it just means that humans are not designed to remember the minutae of collections of words. We remember the thematic aboutness of them, but perhaps not always the smaller details. Having closely read all these plays (though not in this particular edition: I have read the Arden editions, which were much more difficult to stick on one imposing looking shelf), all I remember what they were about, but perhaps not at the level of minutae I might want to have. So today I’m going to illustrate how I might go from sixteen volumes of Shakespeare to a highly specific research question, and to do that, I’m going to start with a calculator.
A calculator is admittedly a rather old and rather simple piece of technology; it’s one that is not particularly impressive now that we have cluster servers that can crunch thousands of data points for us, but it remains useful nonetheless. Without using technology which is more advanced than our humble calculator, I’m going to show how the simple task of counting and a little bit of basic arithmetic can raise some really interesting questions. Straightforward counting is starting to get a bit of a bad rap in digital humanities discourse (cf Jockers and Mimno 2013, 3 and Goldstone and Underwood 2014, 3-4): yes, we can count, but that is simple. We can also complicate this process with calculation and get even more exciting results! This is, of course, true, and provides many new insights to texts which were otherwise unobtainable. Eventually today I will get to more advanced calculation, but for now, let’s stay simple and count some things.
Except that counting is not actually all that simple: decisions have to be made about what to count and how to decide what to count, and then how you are going to do that. I happen to be interested in gender, which I think is one of the more quantifiable social identity variables in textual objects, though it certainly isn’t the only one. Let’s say I wanted to find three historically relevant gendered noun binaries for Shakespeare’s corpus. Looking at the historical thesaurus of the OED for historical contexts, I can decide on lord/lady, man/woman, and knave/wench, as they show a range of formalities (higher – neutral – lower) and these terms are arguably semantically equivalent. The first question I would have is “how often do these terms actually appear in 38 Shakespeare plays?”

Turns out the answer is “not much”: they are right up there in the little red sliver there. My immediate next question would be “what makes up the rest of this chart?” The obvious answer is, of course, that it covers everything that is not our node words in Shakespeare. However, there are two main categories of words contained therein: the frequency of function words (those tiny boring words that make up much of language) and the frequency of content words (words that make up what each play is about). We have answers, but instantly I have another question: what does the breakdown of that little red sliver look like?
This next chart shows the frequency of both the singular and the plural form of each node word, in total, for all 38 Shakespeare plays. There are two instantly noticeable things in this chart: first, the male terms are far more frequent than the female terms, and that wench is not used very much (though we may think of wench as being a rather historical term).

There are more male characters than female characters in Shakespeare – by quite a large margin, regardless of how you choose to divide up gender – but surely they are talking about female characters (as they are the driving force of these plays: either a male character wants to marry or kill a female character). This is not to say that male and female characters won’t talk to each other; there just happens to be a lot more male characters. Biber and Burges (2000) have noted that in 19th century plays, male to male talk is more frequent than male to female talk (and female to female talk). I am not going to claim this is true here, but it seems to be a suggestive model, as male characters dominate speech quantities in the plays. There are lots of questions we can keep asking from this point, and I will return to some of them later, but I want to ask a bigger question: how does Shakespeare’s use of these binaries compare to a larger corpus of his contemporaries, 1512-1662?
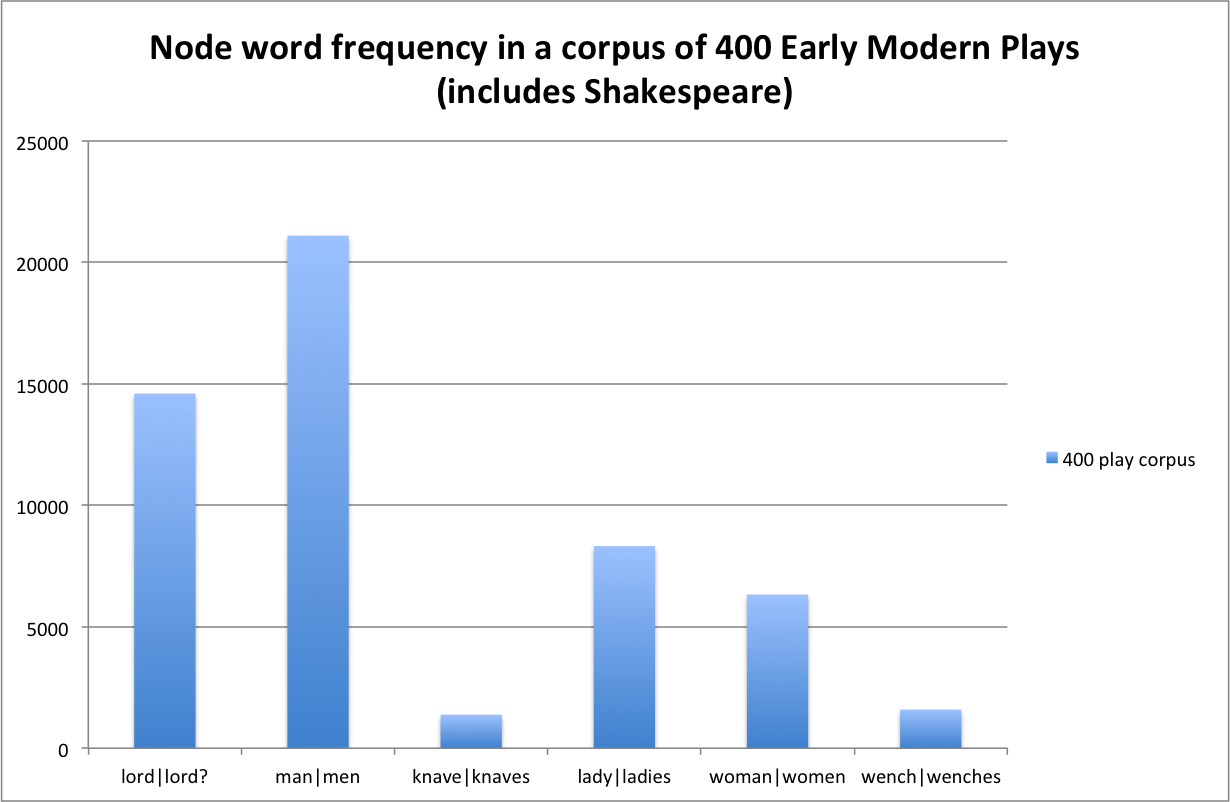
It is worth noting that this corpus contains 332 plays, even though it is called the 400 play corpus; some things, I suppose, sound better when rounded up. These terms are still countable, though, and we see a rather different graph for this corpus:

The 400 play corpus includes Shakespeare, so we are now comparing Shakespeare to himself and 54 other dramatists.[1] The male nouns are noticeably more frequent than the female nouns, which suggests that maybe the proportions of male to female characters from Shakespeare is true here too. Interestingly, lord is less frequent than man, which is the opposite of what we saw previously. The y axis is different for this graph, as this is a much larger corpus than Shakespeare’s, but it seems like the female nouns are consistent.
One glaring problem with this comparison is that I am looking at two different-sized objects. A corpus of 332 plays is going to be, generally speaking, larger than a corpus of 38 plays.[2] McEnery and Wilson note that comparisons of corpora often require adjustment: “it is necessary in those cases to normalize the data to some proportion […] Proportional statistics are a better approach to presenting frequencies” (2003, 83). When creating proportions, Adam Kilgariff notes “the thousands or millions cancel out when we do the division, it makes no difference whether we use thousands or millions” (2009, 1), which follows McEnery and Wilson’s assertion that “it is not crucial which option is selected” (2003, 84). For my proportions, I choose parts per million.

Shakespeare is rather massively overusing lord in his plays compared to his contemporaries, but he is also underusing the female nouns compared to contemporaries. Now we have a few research questions to address, all of which are very interesting:
- Why does Shakespeare use lord so much more than the rest of Early Modern dramatists?
- Why do the rest of Early Modern dramatists use wench so much more than Shakespeare?
- Why is lady more frequent than woman overall in both corpora?
I’m not going to be able to answer all of these today, though they but let’s talk a little bit about lord. This is a pretty noticeable difference for a term which seems pretty typical of Early Modern drama, which is full of noblemen. If I had to guess, I would say that lord might be more frequent in history plays compared to the tragedies or the comedies. I say this because as a reader I know there are most definitely noblemen, and probably defined as such, in these plays.
So what if we remove the histories from Shakespeare’s corpus, count everything up again, and make a new graph comparing Shakespeare minus the histories to all of Shakespeare? By removing the history plays it is possible to see how Shakespeare’s history plays as a unit compare to his comedy & tragedy plays as a unit. [3]

Female nouns fare better in Shakespeare Without Histories than in Shakespeare Overall, possibly because the female characters are more directly involved in the action of tragedies and comedies than they are in histories (though we know the Henry 4 plays are an exception to that), so that is perhaps not all that interesting. What is interesting, though, is the difference between lord in Shakespeare Without Histories and Shakespeare With Histories. What is going on in the histories? How do Shakespeare’s histories compare to all histories in the 400 play corpus?

Now we have even more questions, especially “what on earth is going on with lord in Shakespeare” and “why is wench more frequent in all of the histories?” I’m going to leave the wench question for now, though: not because it’s uninteresting but because it is less noticeable compared to what I’ve been motioning at with lord, which is clearly showing some kind of generic variation.
Remember, we haven’t done anything more complex than counting and a little bit of arithmetic yet, and we have already created a number of questions to address. Now we can create an admittedly low-tech visualization of where in the history plays these terms show up: each black line is one instance, and you read these from left to right (‘start’ to ‘finish’):

And now I instantly have more questions (why are there entire sections of plays without lord? Why do they cluster only in what clearly are certain scenes? etc) but what looks most interesting to me is King John, which has the fewest examples. On a first glance, King John and Richard 3 appear to be outliers (that is, very noticeably different from the others: 42 instances vs 236 instances). Having read King John, I know that there are definitely nobles in the play: King John, King Philip, the Earls of Sudbury, Pembroke, Essex and the excellently named Lord Bigot. And, again, having read the play I know that it is about the relationships between fathers, mothers and brothers – the play centers around Philip the Bastard’s claim to the throne – and also is about the political relationship (or lack thereof) between France and England. From a reader’s perspective, none of that is particularly thematically unique to this play compared to the rest Shakespeare’s history plays, though.
I can now test my reader’s perspective using a statistical measure of keyness called log likelihood, which asks which words are more or less likely to appear in an analysis text compared to a larger corpus. This process will provide us with words which are positively and negatively ranked overall with a ranking of statistical significance (more stars means more statistically significant). Now I am asking the computer to compare King John to all of Shakespeare’s histories. I have excluded names from this analysis, as a reader definitely knows hubert arthur robert philip faulconbridge geoffrey are in this play without the help of the computer.

However, you can see that the absence of lord in King John is highly statistically significant (marked with four *s, compared to others with fewer *s). Now, we saw this already with the line plots, though it is nice to know that this is in fact one of the most significant differences between King John and the rest of the histories.
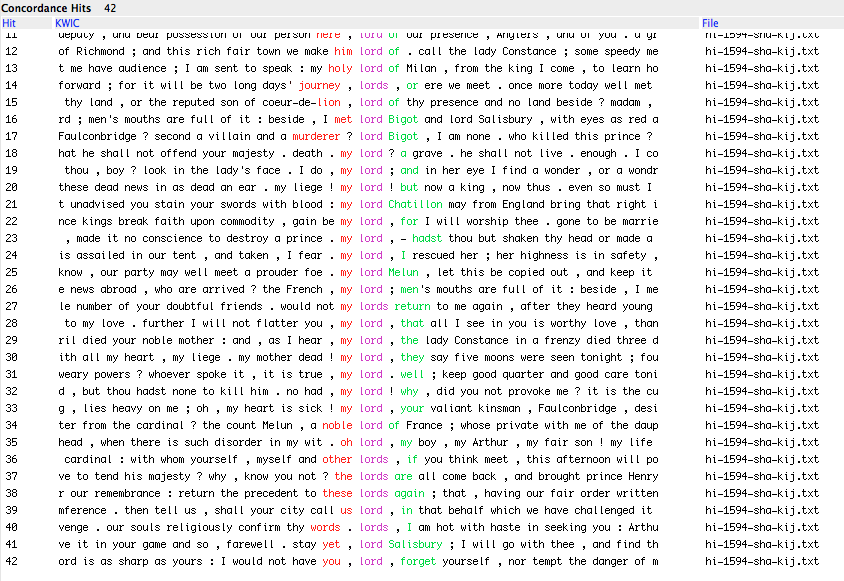
All of this is nice, and very interesting, as it is something we might not have ever noticed as a reader: because it is a history play with lords in it, it is rather safe to assume that it will contain the word lord more often than it actually does. Revisiting E.A.J. Honingmann’s notes on his Arden edition of King John, there have been contentions about the use of king in the First Folio (2007, xxxiii-xliii), most notably around the confusions surrounding King Lewis, King Philip and King John all labeled as ‘king’ in the Folio (see xxxiv-xxxvii for evidence). But none of this is answering our question about lord’s absence. So what is going on with lord? We can identify patterns with a concordancer, and we get a number of my lords:
This is looking like a fairly frequent construction: we might want to see what other words are likely to appear near lord in Shakespeare overall: is my one of them? As readers, we might not notice how often these two words appear together. I should stress that we still have not answered our initial question about lord in King John, though we are trying to.
Using a conditional probability of the likelihood of one lemma (word) to appear next to another lemma (word) in a corpus using the dice coefficiency test, which is the mean of two conditional probabilities: P(w1,w2) and P(w2,w1). Assuming the 2nd word in the bigram appears given the 1st word, and the 1st word in the bigram appears given the 2nd word, this relationship can be computed on a scale from 0-1. 0 would mean there is no relationship; 1 means they always appear together. With this information, you can then show which words are uniquely likely to appear near lord in Shakespeare and contrast that to the kinds of words which are uniquely likely to appear next to lady – and again for the other binaries as well. Interestingly, my only shows up with lord!

This is good, because it shows that lord does indeed appear very differently to our other node words in Shakespeare’s corpus, and suggests that there’s something highly specific going on here with lord, all of which is still suggestive that there is something about lord which is notable. However, I’m still not sure what is happening with lord in King John. Why are there so few instances of it?
Presumably if there is an absence of one word or concept, there will be more of a presence a second word or concept. One such example might be king, but the log-likelihood analysis shows that this is comparatively more frequent in King John than in the rest of Shakespeare’s histories (note the second entry on this list)
Now we have two questions: why is lord so absent, and why is this so present? From here I might go back to our concordance plot visualizations, but this is addressable at the level of grammar: this is a demonstrative pronoun, which Jonathan Hope defines in Shakespeare’s Grammar as “distinguish[ing] number (this/these) and distance (this/these = close; that/those = distant). Distance may be spatial or temporal (for example ‘these days’ and ‘those days’)” (Hope 2003, 24). Now we have a much more nuanced question to address, which a reader would never have noticed: Does King John use abstract, demonstrative pronouns to make up for a lack of the concrete content word lord in the play? I admit I have no idea: does anybody else know?
WORKS CITED
Halliwell-Phillipps, J.O. (1970. [1854].) The works of William Shakespeare, the text formed from a new collation of the early editions: to which are added all the original novels and tales on which the plays are founded; copious archæological annotations on each play; an essay;on the formation of the text; and a life of the poet. New York: AMS press.
“Early English Books Online: Text Creation Partnership”. Available online: http://quod.lib.umich.edu/e/eebogroup/ and http://www.proquest.com/products-services/eebo.html.
“Early English Books Online: Text Creation Partnership”. Text Creation Partnership. Available online: http://www.textcreationpartnership.org/
Anthony, L. (2012). AntConc (3.3.5m) [Computer Software]. Tokyo, Japan: Waseda University. Available from http://www.antlab.sci.waseda.ac.jp/
Biber , Douglas, and Jená Burges. (2000) “Historical Change in the Language Use of Women and Men: Gender Differences in Dramatic Dialogue”. Journal of English Linguistics 28 (1): 21-37.
DEEP: Database of Early English Playbooks. Ed. Alan B. Farmer and Zachary Lesser. Created 2007. Accessed 4 June 2014. Available online:http://deep.sas.upenn.edu.
Froehlich, Heather. (2013) “How many female characters are there in Shakespeare?” Heather Froehlich. 8 February 2013. https://hfroehlich.wordpress.com/2013/02/08/how-many-female-characters-are-there-in-shakespeare/
Froehlich, Heather. (2013). “How much do female characters in Shakespeare actually say?” Heather Froehlich. 19 February 2013. https://hfroehlich.wordpress.com/2013/02/19/how-much-do-female-characters-in-shakespeare-actually-say/
Froehlich, Heather. (2013). “The 400 play corpus (1512-1662)”. Available online: http://db.tt/ZpHCIePB [.csv file]
Goldstone, Andrew, and Ted Underwood. “The Quiet Transformations of Literary Studies: What Thirteen Thousand Scholars Could Tell Us.” New Literary History, forthcoming.
Hope, Jonathan. (2003). Shakespeare’s Grammar. The Arden Shakespeare. London: Thompson Learning.
Jockers, M.L. and Mimno, D. (2013). Significant themes in 19th-century literature. Poetics. http://dx.doi.org/10.1016/j.poetic.2013.08.005
Kay, Christian, Jane Roberts, Michael Samuels, and Irené Wotherspoon (eds.). (2014) The Historical Thesaurus of English. Glasgow: University of Glasgow. http://historicalthesaurus.arts.gla.ac.uk/.
Kilgariff, Adam. (2009). “Simple Maths for Keywords”. Proceedings of the Corpus Linguistics Conference 2009, University of Liverpool. Ed. Michaela Mahlberg, Victorina González Díaz, and Catherine Smith. Article 171. Available online: http://ucrel.lancs.ac.uk/publications/CL2009/#papers
McEnery, Tony and Wilson, Andrew. (2003). Corpus Linguistics: An Introduction. Edinburgh: Edinburgh University Press, 2nd Edition. 81-83
Mueller, Martin. WordHoard. [Computer Software]. Evanston, Illinois: Northwestern University. http://wordhoard.northwestern.edu/
Shakespeare, William. (2007). King John. Ed. E. A. J. Honigmann. London: Arden Shakespeare / Cengage Learning.
[1] Please see http://db.tt/ZpHCIePB [.csv file] for the details of contents in the corpus.
[2] This is not always necessarily true: counting texts does not say anything about how big the corpus is! A lot of very short texts may actually be the same size as a very small corpus containing a few very long texts.
[3] The generic decisions described in this essay have been lifted from DEEP and applied by Martin Mueller at Northwestern University. I am very slowly compiling an update to these generic distinctions from DEEP, which uses Annals of English Drama, 975-1700, 3rd edition, ed. Alfred Harbage, Samuel Schoenbaum, and Sylvia Stoler Wagonheim (London: Routledge, 1989) as its source to Martin Wiggins’ more recent British Drama: A Catalog, volumes 1-3 (Oxford: Oxford UP, 2013a, 2013b, 2013c) for further comparison.

























You must be logged in to post a comment.